BlogPosts
Arabic AL-BERT
Our pretraining procedure follows training settings of bert with some changes: trained for 7M training steps with batchsize of 64, instead of 125K with batchsize of 4096. These models were trained using Google ALBERT’s github repository on a single TPU v3-8 provided for free from TFRC.
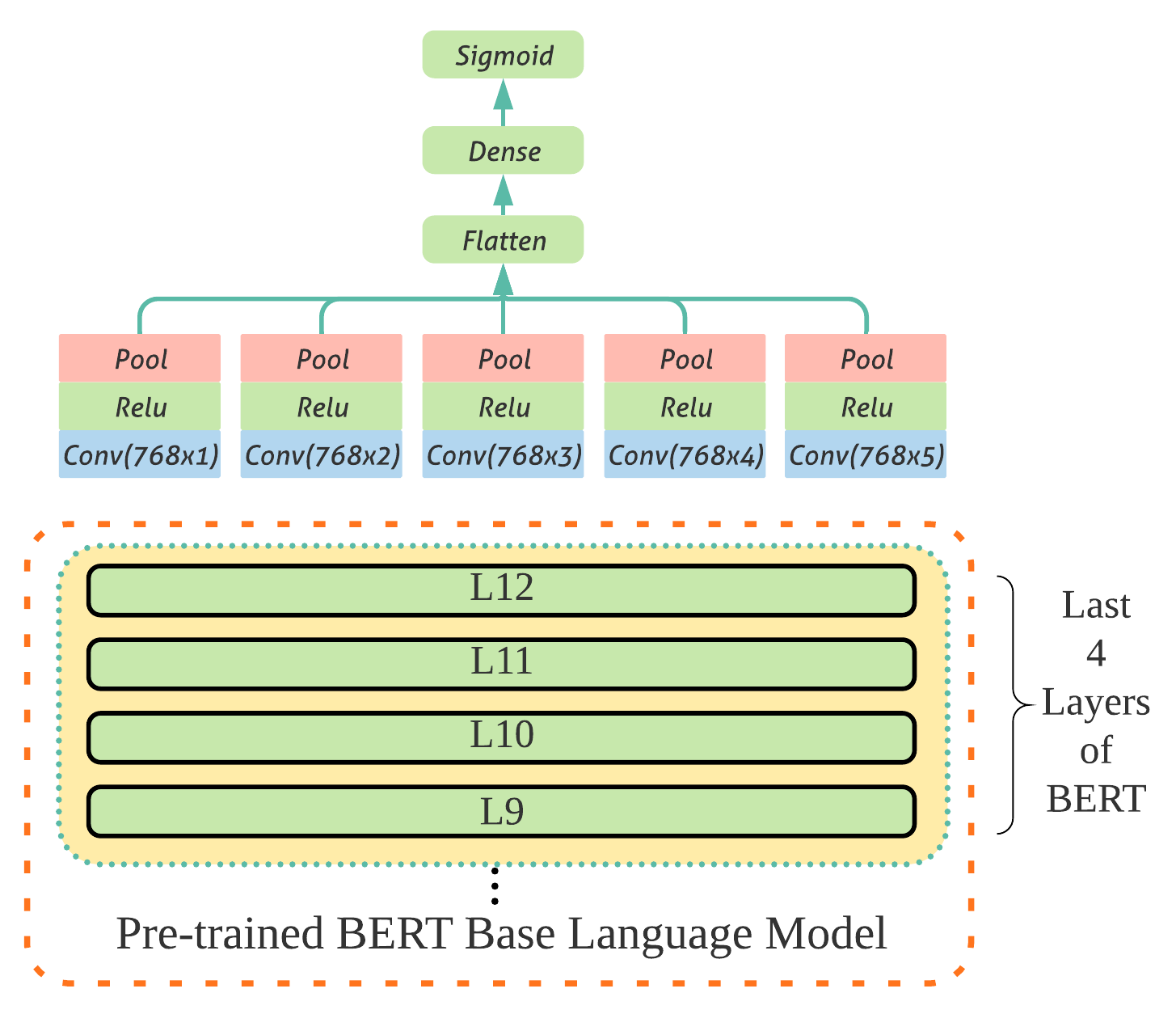
BERT-CNN for Offensive Speech Identification
Recently, we have observed an increase in social media usage and a similar increase in hateful and offensive speech. Solutions to this problem vary from manual control to rule-based filtering systems; however, these methods are time-consuming or prone to errors if the full context is not taken into consideration while assessing the sentiment of the text (Saif et al. 2016).