Fall 2020
3D Perception for Creativity Assistance
We are living in an era where the digital world is becoming an inevitable part of our professional and daily lives. Digital creation tools are essential for many professions including design, entertainment, gaming etc. In our daily lives, we all take many pictures or capture many videos each day to record and share our memories. There is a stronger demand to transform such digital workflows into life-like experiences. My research focuses on enabling such a transformation by developing computational 3D perception tools to reason about the physical environment, people, objects, and how they interact with each other from 2D digital content including images, sketches, and videos. In this talk, I will focus on some of my recent work in this domain, specifically in the context of garment design and 3D reconstruction of man-made shapes. I will provide examples of how 3D perception can enable 2D creative tools for Adobe’s products and discuss some of the open research challenges.
January 19, 2021
Pouya Niaz (Koç University)
Estimation of human force in physical human-robot interaction (pHRI) via machine/deep learning
In physical human-robot interaction (pHRI), a human and a robot perform a collaborative task while being in physical contact with one another. In such a system, the robot needs to understand human intentions and comply with them for successful and efficient interaction. One of the sensory modalities that emerge in this regard is the haptics (sense of touch). Our earlier studies on human dyads show that partners can successfully understand each other’s intentions during a collaborative manipulation task using force cues. In pHRI, the robot is typically equipped with a force sensor, while there is no force sensor on the human side. Being able to estimate human force in pHRI could enable the robot to anticipate human intention and adapt accordingly. This is challenging due to the changing nature of task phases and human behavior. In our studies, we estimate human force using ML/DL techniques based on the data collected from a realistic pHRI scenario that involves a human operator drilling a hole in a workpiece by collaborating with a robot. Our robotic experiments so far have utilized fixed and variable integer-order and fractional-order admittance controllers for commanding the robot. We have been largely successful in our force estimation efforts, albeit it is a work in progress, and believe that our methods can effectively be used in similar pHRI scenarios as well.
January 5, 2021
Mete Tuluhan Akbulut & Yunus Skere (Bogazici University)
Learning from Demonstration with Deep Learning and Adaptation to the Outside of Training Range
In this joint talk, we will present our recent learning from demonstration (LfD) framework and an adaptive learning framework based on this LfD framework. First, we will present Conditional Neural Movement Primitives (CNMP) framework that is designed as a robotic movement learning and generation system built on top of a recent deep neural architecture, namely Conditional Neural Processes (CNP). Based on CNP, CNMP extracts the prior knowledge directly from the training data by sampling observations from it and uses it to predict a conditional distribution over any other target points. CNMP specifically learns complex temporal multi-modal sensorimotor relations in connection with external parameters and goals; produces movement trajectories in joint or task space, and executes these trajectories through a high-level feedback control loop. Second, we will present Adaptive Conditional Neural Movement Primitives (ACNMP) that allows efficient policy improvement in novel environments and effective skill transfer between different agents. This is achieved through exploiting the latent representation learned by the underlying Conditional Neural Process (CNP) model, and simultaneous training of the model with supervised learning (SL) for acquiring the demonstrated trajectories and via RL for new trajectory discovery. Furthermore, ACNMPs can be used to implement skill transfer between robots having different morphology by forming a common latent representation space.

December 29, 2020
Tolga Birdal (Stanford University)
Learning on 3D Representations with Applications to Camera/Object Pose Estimation and Registration
With the advances in autonomous driving, robotics and geospatial mapping, utilization of raw 3D data in order to perform SLAM, scene understanding or 3D reconstruction, started to attract tremendous attention from vision scholars. However, due to its unstructured and sparse nature, it is not immediate to transfer the powerful and well established tools of 2D computer vision to 3D domain. First of the key issues is finding the suitable representation. The second arises when the keypoint/descriptor driven pipelines essential in 2D are to be extended to 3D. This is due to the fact that 3D geometry lacks the well defined notion of local reference frames, and a 3D patch is significantly less informative than an appearance based 2D one. Last but not least, describing the factors of variation such as object/camera pose is significantly more challenging due to the increased degrees of freedom. In defense of 3D geometric deep neural networks and arguing in favor of point cloud representations, Tolga will first introduce the state of the art techniques for processing 3D data. He then moves onto the advances in local feature extraction and 3D pose estimation. If time permits, Tolga will also talk about uncertainty aware architectures for handling ambiguous cases.

CRAFT: A Benchmark for Causal Reasoning About Forces and inTeractions
Recent advances in Artificial Intelligence and deep learning have revived the interest in studying the gap between the reasoning capabilities of humans and machines. In this ongoing work, we introduce CRAFT, a new visual question answering dataset that requires causal reasoning about physical forces and object interactions. It contains 38K video and question pairs that are generated from 3K videos from 10 different virtual environments, containing different number of objects in motion that interact with each other. Two question categories from CRAFT include previously studied descriptive and counterfactual questions. Besides, inspired by the theory of force dynamics from the field of human cognitive psychology, we introduce new question categories that involve understanding the intentions of objects through the notions of cause, enable, and prevent. Our preliminary results demonstrate that even though these tasks are very intuitive for humans, the implemented baselines could not cope with the underlying challenges.

Self-Supervised Learning Through The Eyes of a Child.
Within months of birth, children develop meaningful expectations about the world around them. How much of this early knowledge can be explained through generic learning mechanisms applied to sensory data, and how much of it requires more substantive innate inductive biases? Addressing this fundamental question in its full generality is currently infeasible, but we can hope to make real progress in more narrowly defined domains, such as the development of high-level visual categories, thanks to improvements in data collecting technology and recent progress in deep learning. In this paper, our goal is precisely to achieve such progress by utilizing modern self-supervised deep learning methods and a recent longitudinal, egocentric video dataset recorded from the perspective of three young children (Sullivan et al., 2020). Our results demonstrate the emergence of powerful, high-level visual representations from developmentally realistic natural videos using generic self-supervised learning objectives.

Acoustic and Language Model Adaptations In Privacy-Preserving Dialogue Systems
Current automatic speech recognition (ASR) systems trained on native speech often perform poorly when applied to non-native or accented speech. There are several causes for this, including speaker differences, variability in the acoustic environment, and the domain of use as well. Adaptation algorithms attempt to alleviate the mismatch between source and target domain data. In this presentation, I first focus on the acoustic model adaptation to improve the recognition of multi-accent data comprising native, non-native, and accented speech. I investigate the x-vector-like accent embeddings as auxiliary inputs during acoustic model training inside the Kaldi toolkit. In contemporary ASR systems, a language model plays an essential role in guiding the search among the word candidates and has a decisive effect on the ASR quality. In the second part of my talk, I introduce another related problem in a privacy-preserving setting. Transcribed text in any ASR task often provides sufficient clues to identify sensitive information related to users. Likewise in the acoustic model scenario, a language model adaptation is also crucial to use privacy-removed text in any ASR system. Therefore, I examine a domain adaptation scheme of privacy-preserving text representations by combining word-class n-grams and LSTM-based language models

November 24, 2020
Atilim Gunes Baydin
Probabilistic Programming for Inverse Problems in Physical Sciences
Machine learning enables new approaches to inverse problems in many fields of science. We present a novel probabilistic programming framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol, which allows general-purpose inference engines to record and control random number draws within simulators in a language-agnostic way. The execution of existing simulators as probabilistic programs enables highly interpretable posterior inference in the structured model defined by the simulator code base. We demonstrate the technique in particle physics, on a scientifically accurate simulation of the tau lepton decay, which is a key ingredient in establishing the properties of the Higgs boson. Inference efficiency is achieved via amortized inference where a deep recurrent neural network is trained to parameterize proposal distributions and control the stochastic simulator in a sequential importance sampling scheme, at a fraction of the computational cost of a Markov chain Monte Carlo baseline.

November 17, 2020
Ammar Rasid
Embeddings-Based Clustering for Target Specific Stances: The Case of a Polarized Türkiye
We propose an unsupervised user stance detection method to capture fine grained divergences in a community across various topics. We employ pre-trained universal sentence encoders to represent users based on the content of their tweets on a particular topic. User vectors are projected onto a lower dimensional space using UMAP, then clustered using HDBSCAN. Our method performs better than previous approaches on two datasets in different domains, achieving precision and recall scores ranging between 0.89 and 0.97. We compiled a dataset of more than 300k tweets about UEFA Super Cup’s 2019 final, and tagged 12k users as Liverpool FC or Chelsea FC fans. We utilized our method to analyze the stances of Twitter users noting a correlation between user stances towards various polarizing issues. We used the resultant clusters to quantify the polarization in various topics, and analyze the semantic divergence between clusters.
November 10, 2020
Alpay Sabuncuoglu
Affordable Early Programming Education with Shared Smartphones and Easy-to-Find Materials
Programming education has become an integral part of the primary school curriculum. However, most programming practices rely heavily on computers and electronics which causes inequalities across contexts with different socioeconomic levels. Our learning environments introduces a new and convenient way of using tangibles for coding in classrooms. Our programming environment, Kart-ON, is designed as an affordable means to increase collaboration among students and decrease dependency on screen-based interfaces. Kart-ON is a tangible programming language that uses everyday objects such as paper, pen, fabrics as programming objects and employs a mobile phone as the compiler. Our preliminary studies with children show that Kart-ON boosts active and collaborative student participation in the tangible programming task, which is especially valuable in crowded classrooms with limited access to computational devices. In the meeting, we plan to use Kart-ON and other programming environments together and discuss how AI can enhance the access to quality education with increasing affordable use of smartphones.
November 3, 2020
Ilker Kesen
Research Progress on Visually Grounded Language Learning
In this presentation, I’ll talk about my research focus and recent advances I’ve made. I’ll define what visually grounded language learning is, and then introduce visually grounded language learning problems by categorizing them. I’ll share recent advances for two different projects: image segmentation from referring expressions and visual question answering in a simulated 2-dimensional physics environment.

Self-supervised Visual Representation Learning from Videos
Recent methods based on self-supervised learning have shown remarkable progress and are now able to build features that are competitive with features built through supervised learning. However, the research focus is on learning transferable representations from i.i.d data, e.g. images. To be really applicable, the networks are still required to finetune with manual annotations on downstream tasks, which is always not satisfactory. In this talk, I will cover self-supervised visual representation learning from videos, and explain why I think videos are the perfect data source for self-supervised learning. Specifically, I will present our recent efforts in visual learning representation (from videos) that can benefit semantic downstream tasks, exploiting the rich information in videos, e.g. temporal information, motions, audios, narrations, spatial-temporal coherence, etc. Apart from evaluating the transferability, representation learned from videos are able to directly generalize to downstream tasks with zero annotations ! As a conclusion, I would like to summarize the shortcomings of our works and some preliminary thoughts on how they may be addressed to push the community forward.
October 6, 2020
Ulas Sert
Training a Bridge Bidding Agent using Minimal Feature Engineering and Deep Reinforcement Learning
The game of contract bridge, or just bridge, is a four player imperfect information card game where two partnerships of two players compete against each other. It has two main phases: bidding and play. While the computer players have approached human level performance two decades ago in the playing phase, bidding is still a very challenging problem. This makes bridge one of the last popular games where computers still lag behind expert human level performance. During bidding, players only know their own cards while participating in a public auction. Performing well in this phase requires the players to figure out how to communicate with their partners using the limited vocabulary of bids to decide on a joint contract. This communication is restricted by the strict ordering of legal bids, and can be negatively interfered by bids made by the opponent partnership. In this thesis, we experiment with several novel architectures with minimal feature engineering and evaluate them by using supervised training over a data set of expert level human games. After that we further study different forms of deep reinforcement learning in order refine the resulting model by simulated game play. Lastly, we propose an oracle evaluation metric that can measure the quality of any bidding sequence with respect to the game-theoretical optimum.

HoughNet: Integrating Near and Long-Range Evidence for Bottom-Up Object Detection
This work presents HoughNet, a one-stage, anchor-free, voting- based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log- polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet’s best model achieves 46.4 AP (and 65.1 AP50), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in another task, namely, “labels to photo” image generation by integrating the voting module of HoughNet to two different GAN models and showing that the accuracy is significantly improved in both cases. Code is available at https://github.com/nerminsamet/houghnet.
The Independence Assumption in Computer Vision
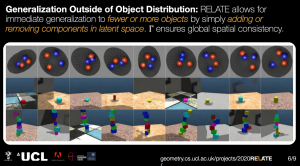
In this joint talk, we will present our recent work that challenges the ‘independence’ assumption in Computer Vision. We will start by presenting RELATE, an object-centric generative model that can generate scene component-wise. As opposed to current state-of-the-art models, RELATE does not assume each object positions to be independent but rather correlated. We introduce a model inspired by neural physics literature that models such correlation at the core of its architecture. We show that this is amenable to a more physically plausible scene generation which can extend to video prediction. We will follow by presenting a novel method to compute correspondences between two images. In general correspondences between images are established using a detect and describe approach were key points are extracted independently for each image and are keypoints are then matched based on a distance function. However, this is generally not robust to large changes in point of view or illumination. In this presentation, we will present D2D, a method that extracts keypoints conditioned on both images. Instead of assuming key points to be independent, we extract them with the knowledge of the image we would like to match. This makes our method robust to large changes in viewpoints and illumination.
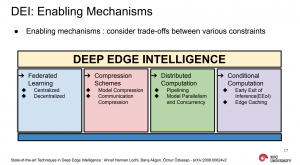
State-of-the-art Techniques in Deep Edge Intelligence
This talk provides an overview of Deep learning based Edge Intelligence and the main design philosophies being utilized to implement Deep Learning at the Network Edge. We discuss why Edge Intelligence is going to be a major way forward followed by ways in which DL models are being implemented in the face of severe resource limitations, security issues and communication requirements and cover some potential research directions.