Fall 2021

Jan 26, 2022
Weights & Biases
ML Model Optimization with Weights & Biases
We had our very first tutorial talk!
Weights & Biases introduced their platform to monitor training of neural network models.
Jan 12, 2022
Raffaella Bernardi, University of Trento
Two Challenges Behind Visual Dialogues: Grounding Negation and Asking an Informative Question
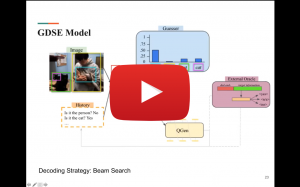
Visual Dialogues are an intriguing challenge for the Computer Vision and Computational Linguistics communities. They involve both understanding multimodal inputs as well as generating visually grounded questions. We take the GuessWhat?! game as test-bed since it has a simple dialogue structure — Yes-No question answer asymmetric exchanges. We wonder to which extent State-Of-The-Art models take the answers into account and in particular whether they handle positively/negatively answered questions equally well. Moreover, the task is goal oriented: the questioner has to guess the target object in an image. As such it is well suited to study dialogue strategies. SOTA systems are shown to generate questions that, although grammatically correct, often lack an effective strategy and sound unnatural to humans. Inspired by the cognitive literature on information search and cross-situational word learning, we propose Confirm-it, a model based on a beam search re-ranking algorithm that guides an effective goal-oriented strategy by asking questions that confirm the model’s conjecture about the referent. We show that dialogues generated by Confirm-it are more natural and effective than beam search decoding without re-ranking. The work is based on the following publications: Alberto Testoni, Claudio Greco and Raffaella Bernardi Artificial Intelligence models do not ground negation, humans do. GuessWhat?! dialogues as a case study Front.ers in Big Data doi: 10.3389/fdata.2021.736709 Alberto Testoni, Raffaella Bernardi “Looking for Confirmations: An Effective and Human-Like Visual Dialogue Strategy”. In Proceedings of EMNLP 2021 (Short paper).
Jan 5, 2022
Ayşegül Dündar, Bilkent University
Controllable Image Synthesis
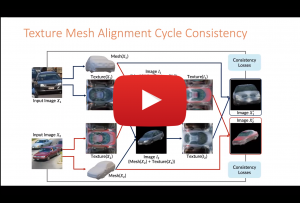
With GAN based models achieving realistic image synthesis on various objects, there has been an increased interest to deploy them for gaming, robotics, architectural designs, and AR/VR applications. However, such applications also require full controllability on the synthesis. To enable controllability, image synthesis has been conditioned on various inputs such as semantic maps, keypoints, and edges to name a few. With these methods, control and manipulation over generated images are still limited. In a new line of research, methods are proposed to learn 3D attributes from images for precise control on the rendering. In this talk, I will cover a range of image synthesis works, starting with conditional image synthesis and continue with 3D attributes learning from single view images for the aim of image synthesis.
Dec 29, 2021
Ayça Atabey, Bilgi IT Law and UN Women
An Interdisciplinary Look at Fairness in AI-driven Assistive Technologies: Mapping Value Sensitive Design (Human-Computer Interaction) onto Data Protection Principles
Value sensitive design (VSD) in Human-Computer Interaction is an established method for integrating values into technical design. Design of AI-driven technologies for vulnerable data subjects requires a particular attention to values such as transparency, fairness, and accountability. To achieve this, there is a need for an interdisciplinary look to the fairness principle in data protection law to bridge the gap between what the law requires and what happens in practice. This talk explores the interdisciplinary approach to Fairness in AI-driven Assistive Technologies through mapping VSD onto Data Protection rules.

Dec 22, 2021
Iacer Calixto, University of Amsterdam & New York University
VALSE : A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
I will talk about a recent collaborative work on VALSE (Vision And Language Structured Evaluation), a novel benchmark designed for testing general-purpose pretrained vision and language (V&L) models for their visio-linguistic grounding capabilities on specific linguistic phenomena. VALSE offers a suite of tests covering various linguistic constructs. Solving these requires models to ground linguistic phenomena in the visual modality, allowing more fine-grained evaluations than hitherto possible. We build VALSE using methods that support the construction of valid foils, and report results from evaluating five widely-used V&L models. Our experiments suggest that current models have considerable difficulty addressing most phenomena. Hence, we expect VALSE to serve as an important benchmark to measure future progress of pretrained V&L models from a linguistic perspective, complementing the canonical task centred V&L evaluations.
Dec 15, 2021
Sıla Kurugol, Harvard Medical School
Quantification of Clinically Useful Information from 3D and 4D MR Images: Computational and Deep Learning Techniques for Image Reconstruction, Motion Compensation and Quantitative Parameter Estimation
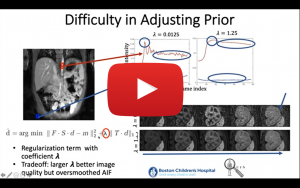
The talk will focus on the use of medical imaging, computational and deep learning techniques for the discovery and quantification of clinically useful information from 3D and 4D medical images. The talk will describe how computational techniques or deep learning methods can be used for the reconstruction of MR images from undersampled (limited) data for accelerated MR imaging, motion-compensated imaging and robust quantitative parameter estimation and image analysis. It will also show the clinical utility of these proposed techniques for the interpretation of medical images and extraction of important clinical markers in applications such as functional imaging of kidneys and Crohn’s disease.

Dec 1, 2021
Jan-Philipp Fränken, University of Edinburgh
Algorithms of Adaptation in Inductive Inference
We investigate the idea that human concept inference utilizes local incremental search within a compositional mental theory space. To explore this, we study judgments in a challenging task, where participants actively gather evidence about a symbolic rule governing the behavior of a simulated environment. Participants construct mini-experiments before making generalizations and explicit guesses about the hidden rule. They then collect additional evidence themselves (Experiment 1) or observe evidence gathered by someone else (Experiment 2) before revising their own generalizations and guesses. In each case, we focus on the relationship between participants’ initial and revised guesses about the hidden rule concept. We find an order effect whereby revised guesses are anchored to idiosyncratic elements of the earlier guesses. To explain this pattern, we develop a family of process accounts that combine program induction ideas with local (MCMC-like) adaptation mechanisms. A particularly local variant of this adaptive account captures participants’ revisions better than a range of alternatives. We take this as suggestive that people deal with the inherent complexity of concept inference partly through use of local adaptive search in a latent compositional theory space.
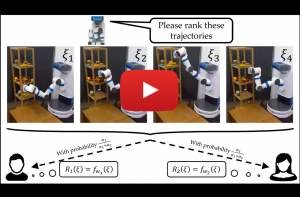
Nov 22, 2021
Erdem Bıyık, Stanford University
Learning Preferences for Interactive Autonomy
In human-robot interaction or more generally multi-agent systems, we often have decentralized agents that need to perform a task together. In such settings, it is crucial to have the ability to anticipate the actions of other agents. Without this ability, the agents are often doomed to perform very poorly. Humans are usually good at this, and it is mostly because we can have good estimates of what other agents are trying to do. We want to give such an ability to robots through reward learning and partner modeling. In this talk, I am going to talk about active learning approaches to this problem and how we can leverage preference data to learn objectives. I am going to show how preferences can help reward learning in the settings where demonstration data may fail, and how partner-modeling enables decentralized agents to cooperate efficiently.

Nov 3, 2021
Zaid Rassim Mohammed Al-Saadi, Koç Univesity
A Novel Haptic Feature Set for the Classification of Interactive Motor Behaviors in Collaborative Object Transfer
Haptics provides a natural and intuitive channel of communication during the interaction of two humans in complex physical tasks, such as joint object transportation. However, despite the utmost importance of touch in physical interactions, the use of haptics is under-represented when developing intelligent systems. This study explores the prominence of haptic data to extract information about underlying interaction patterns within physical human-human interaction (pHHI). We work on a joint object transportation scenario involving two human partners, and show that haptic features, based on force/torque information, suffice to identify human interactive behavior patterns. We categorize the interaction into four discrete behavior classes. These classes describe whether the partners work in harmony or face conflicts while jointly transporting an object through translational or rotational movements. In an experimental study, we collect data from 12 human dyads and verify the salience of haptic features by achieving a correct classification rate over 91% using a Random Forest classifier.

Oct 26, 2021
Laura Leal-Taixé from Technical University of Munich
Shifting Paradigms in Multi-Object Tracking
The challenging task of multi-object tracking (MOT) requires simultaneous reasoning about track initialization, identity, and spatiotemporal trajectories. This problem has been traditionally addressed with the tracking-dy-detection paradigm. In this talk, I will discuss more recent paradigms, most notably, tracking-by-regression, and the rise of a new paradigm: tracking-by-attention. In this new paradigm, we formulate MOT as a frame-to-frame set prediction problem and introduce TrackFormer, an end-to-end MOT approach based on an encoder-decoder Transformer architecture. Our model achieves data association between frames via attention by evolving a set of track predictions through a video sequence. The Transformer decoder initializes new tracks from static object queries and autoregressively follows existing tracks in space and time with the new concept of identity preserving track queries. Both decoder query types benefit from self- and encoder-decoder attention on global frame-level features, thereby omitting any additional graph optimization and matching or modeling of motion and appearance. At the end of the talk, I also want to discuss some of our work in collecting data for tracking with data privacy in mind.
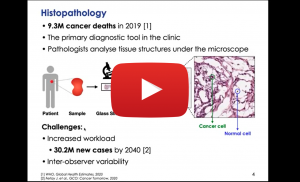
Oct 21, 2021
Mustafa Ümit Öner from National University of Singapore
How strong are the weak labels in digital histopathology?
Histopathology is the golden standard in the clinic for cancer diagnosis and treatment planning. Recently, slide scanners have transformed histopathology into digital, where glass slides are digitized and stored as whole-slide-images (WSIs). WSIs provide us with precious data that powerful deep learning models can exploit. However, a WSI is a huge gigapixel image that traditional deep learning models cannot process. Besides, deep learning models require a lot of labeled data. Nevertheless, most WSIs are either unannotated or annotated with some weak labels indicating slide-level properties, like a tumor slide or a normal slide. This seminar will discuss our novel deep learning models tackling huge images and exploiting weak labels to reveal fine-level information within the images. Firstly, we developed a weakly supervised clustering framework. Given only the weak labels of whether an image contains metastases or not, this framework successfully segmented out breast cancer metastases in the lymph node sections. Secondly, we developed a deep learning model predicting tumor purity (percentage of cancer cells within a tissue section) from digital histopathology slides. Our model successfully predicted tumor purity in eight different TCGA cohorts and a local Singapore cohort. The predictions were highly consistent with genomic tumor purity values, which were inferred from genomic data and accepted as accurate for downstream analysis. Furthermore, our model provided tumor purity maps showing the spatial variation of tumor purity within sections, which can help better understand the tumor microenvironment.
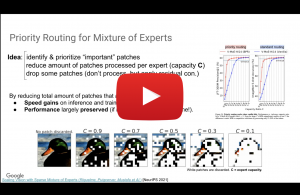
Oct 20, 2021
Barret Zoph from Google Brain
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) models defy this and instead select different parameters for each incoming example. The result is a sparsely-activated model – with an outrageous number of parameters – but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs, and training instability. We address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques mitigate the instabilities, and we show large sparse models may be trained, for the first time, with lower precision formats. We design models based off T5-Base and T5-Large (Raffel et al., 2019) to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus”, and achieve a 4x speedup over the T5-XXL model.
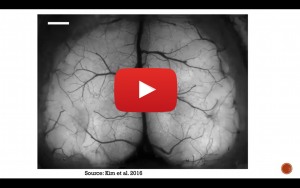
Oct 12, 2021
Fatih Dinç, Stanford University
Uncovering The Neural Circuitry in The Brain Using Recurrent Neural Networks
The talk is structured in two parts. The first part focuses on the developments in recurrent neural network training algorithms over the years. We first identify the types of recurrent neural networks currently used in neuroscience research based on the training properties and target function. Here, we will discuss the seminal work by Sompolinsky and Crisanti from 1988 regarding chaos in random neural networks, the reservoir computing paradigm, back-propagation through time, and neural activation (not output) based training algorithms. In the second part, we will go through a selection of papers from neuroscience literature using these methods to uncover the neural circuitry in the brain. As machine learning and neuroscience literature have always inspired progress in each other, there is a high chance that some of these biological findings might have direct relevance in artificial neural network research. We will conclude with some candidate ideas.
Oct 6, 2021
Ali Hürriyetoğlu, Koç University
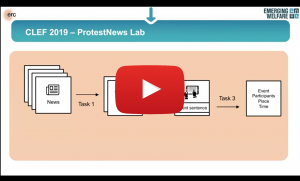
Challenging the Standards for Socio-Political Event Information Collection
Spatio-temporal distribution of socio-political events sheds light on the causes and effects of government policies and political discourses that resonate in society. Socio-political event data is utilized for national and international policy- and decision-making. Therefore, the reliability and validity of these datasets are of utmost importance. I will present a summary of my studies that examine common assumptions made during creating socio-political event databases such as GDELT and ICEWS. The assumptions I tackled have been 1) keyword filtering is an essential step for determining the documents that should be analyzed further, 2) a news report contains information about a single event, 3) sentences that are self-contained in terms of event information coverage are the majority, and 4) automated tool performance on new data is comparable to the performance on the validation setting. Moreover, I will present how my work brought the computer science and socio-political science communities together to quantify state-of-the-art automated tool performances on event information collection in cross-context and multilingual settings in the context of a shared task and workshop series, which are ProtestNews Lab @ CLEF 2019, COPE @ Euro CSS 2019, AESPEN @ LREC 2020, and CASE @ ACL 2021, I initiated.
Sep 28, 2021
Abdul Basit Anees and Ahmet Canberk Baykal, KUIS AI MSc Fellows
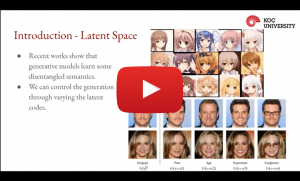
Text-Guided Image Manipulation Using GAN Inversion
Recent GAN models are capable of generating very high-quality images. Then, a very important follow-up problem is, how to control these generated images. A careful analysis of the latent space of GANs suggests that this control can be achieved by manipulating the latent codes in a desired direction. In this talk, we will be presenting our model that is capable of modifying images in such a way that they have some desired attributes corresponding to any text description. For this purpose, we use the idea of GAN inversion. Our model makes use of two encoders to invert the images along with their textual descriptions to the latent space of a pre-trained StyleGAN model. Additionally, we utilize OpenAI’s Contrastive Language-Image Pre-training (CLIP) model to enforce the latent codes to be aligned with the desired textual descriptions. The inverted latent codes are fed to the StyleGAN generator to obtain the manipulated images. We conducted experiments on face datasets and compared our results with the related work.

Sep 21, 2021
Cagatay Yildiz, Aalto University, Finland
Continuous-Time Model-Based Reinforcement Learning
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. Such discrete-time approximations typically lead to inaccurate dynamic models, which in turn deteriorate the control learning task. In this talk, I will describe an alternative continuous-time MBRL framework for RL. Our approach infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We also propose a novel continuous-time actor-critic algorithm for policy learning. Our experiments illustrate that the model is robust against irregular and noisy data, is sample-efficient, and can solve control problems which pose challenges to discrete-time MBRL methods.

Sep 14, 2021
Deqing Sun, Google Research
Learning Optical Flow: from Model to Data
Optical flow provides important motion information about the dynamic world and is of fundamental importance to many tasks. In this talk, I will discuss two different aspects of learning optical flow: model and data. I will start with the background and classical approach to optical flow. Next, I will talk about PWC-Net, a compact and effective model built using classical principles for optical flow. Finally, I will introduce AutoFlow, a simple and effective method to render training data for optical flow that optimizes the performance of a model on a target dataset.

Tightly Connecting Vision and Language: Localized Narratives and Beyond
Localized Narratives are a new form of multimodal image annotations connecting vision and language: annotators describe an image with their voice while simultaneously hovering their mouse over the region they are describing. Since the voice and the mouse pointer are synchronized, we can localize every single word in the description. Based on and inspired by this data, we first designed a new image retrieval modality by “speaking and pointing”, which comes naturally to humans and we show it works very well in practice. Second, we robustly matched the noun phrases in the captions to the panoptic categories in COCO to provide a dense pixel grounding. With this new data, we propose the new task of Panoptic Narrative Grounding and present a very solid baseline that, given an image caption, outputs a segmentation that grounds all their nouns.