Computer Vision
In Computer Vision, we analyze visual data to recognize and understand the world captured by cameras as images or video sequences. The visual data can mathematically be represented as a matrix of numbers. This allows us to do interesting analyses by investigating various relationships between these numbers either on the matrix of a single image or across matrices of different images.
One of the main challenges in Computer Vision is to map from low-level sensory info like pixels to higher-level semantic concepts like objects by bridging the so-called semantic gap. For example, we can detect obstacles on the road for a self-driving system by learning to recognize particular patterns that obstacles on road images typically display.
In order to do visual analysis, we use Machine Learning, in particular, Deep Learning by learning relationships between numbers corresponding to pixels. Deep Learning algorithms work by analyzing several samples of images displaying certain properties that we want to detect or recognize. In the obstacle detection example, we present the deep neural network several examples of road images containing obstacles in various positions, scales, and color. The network learns to recognize common patterns across different samples of obstacles during training and then, it can detect obstacles on unseen test images.
Semantic Understanding
Associating pixels with a semantic meaning is the most general form of Computer Vision. The world is composed of objects or stuff like vegetation or sky whose projections create semantic regions with certain properties on the image. We learn to recognize or detect these properties to extract semantic information from visual data.
3D Vision

Images and videos are 2D projections of the 3D world. In 3D Vision, our goal is to recover the depth axis of images that is lost after projection. For estimating depth, we traditionally model geometric relationships between left and right images from stereo cameras resembling our two eyes. More recently, we can learn to estimate depth from consecutive frames from a single camera.
In addition to depth estimation, we also work on directly analyzing 3D data captured by sensors like Kinect or Lidar.
Dynamic Vision

The world around is dynamic and the effects of moving objects or a moving camera are directly observable on visual data. We work on motion modeling algorithms ranging from the motion of pixels to the motion of objects. The task of tracking pixels between consecutive frames is called Optical Flow. Pixels that do not belong to an object, i.e. in the background, collectively move from one frame to another only according to camera motion. We work on modeling camera motion by discovering background pixels affected by it.
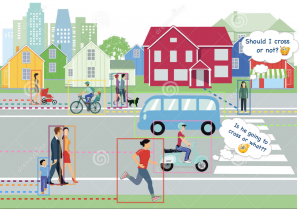
In addition to tracking pixels, we also work on tracking objects like vehicles and pedestrians in crowded street scenes. For tracking a single object, we model changes in object appearance through time. For tracking multiple objects, we learn to model relations between several objects. As a natural extension to tracking, we can predict the behavior or intent of each object, i.e. future prediction.
We work on Computer Vision problems from various domains including:
- Robot vision
- Self-driving cars
- Human-computer interaction
- Medicine
- Scene modeling
- Vision and language