Summer 2021
August 17, 2021
Tunca Doğan, Hacettepe University
Development and Application of Data-Driven Approaches to Make Sense out of Large-Scale and Heterogeneous Biomolecular Data
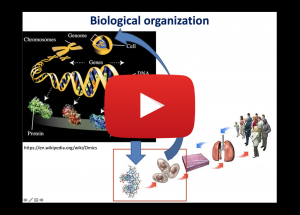
The recent availability of inexpensive technologies led to a surge of biological/biomedical data production and accumulation in public servers. These noisy, complex and large-scale data should be analyzed in order to understand mechanisms that constitute life and to develop new and effective treatments against prevalent dieases. A key concept in this endeavour is the prediction of unknown attributes and properties of biomolecules (i.e., genes, proteins and RNAs) such as their molecular functions, physical interactions and etc., together with their relationships to high-level biomedical concepts such as systems and diseases. Lately, cutting-edge data-driven approaches are started to be applied to biological data to aid the development of novel and effective in silico solutions. In this seminar, I’ll summarize our efforts for integrating and representing heterogeneous data from different biological/biomedical data resources (i.e., the CROssBAR project) together with the development and application of deep learning-based computational methods for enriching the integrated data by predicting unknown functions and drug discovery centric ligand interactions of human genes and proteins. These tools and services are developed with the aim of helping researchers from diverse fields of the life-sciences domain in building and pre-evaluating their hypothesis, before planning and executing costly and risky experimental/clinical studies.

August 10, 2021
Ahsan Ali, Argonne National Lab, USA
Towards Scalable and Adaptive Machine Learning Design and Training
Machine-Learning-as-a-Service (MLaaS) aims to support the optimized execution of machine learning (ML) tasks on cloud infrastructure. Existing MLaaS systems are mainly built atop conventional VM- based architectures and suffer from slow scaling, are cost-inefficient, and require extensive domain expertise to optimize the training deployment and execution. Moreover, ML training tasks often have varying resource demands across different training phases, which adds to the complexity. To address these challenges, we propose SMLT, an automated, scalable, and adaptive framework to perform ML design and training on cloud infrastructure. By embracing the emerging serverless computing paradigm, SMLT provides flexibility and cost-efficiency. By employing a hierarchical model synchronization mechanism, SMLT addresses the challenge of poor inter-connections between serverless functions. In addition, we design an automated and adaptive scheduling mechanism to dynamically optimize the deployment and resource scaling for ML tasks during training. SMLT supports all major ML frameworks and is open-sourced. The experimental evaluation with large, sophisticated modern ML models demonstrates that SMLT outperforms the state-of-the-art MLaaS systems and existing serverless ML training frameworks in both performances (up to 8x) and monetary cost (up to 2x).
July 29, 2021
Berkay Köprü, Koc University
Use of Affective Visual Information for Summarization of Human-Centric Videos
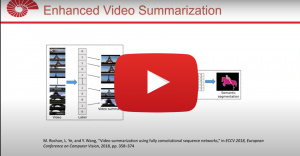
Increasing volume of user-generated human-centric video content and their applications, such as video retrieval and browsing, require compact representations that are addressed by the video summarization literature. Current supervised studies formulate video summarization as a sequence-to-sequence learning problem and the existing solutions often neglect the surge of human-centric view, which inherently contains affective content. In this study, we investigate the affective-information enriched supervised video summarization task for human-centric videos. First, we train a visual input-driven state-of-the-art continuous emotion recognition model (CER-NET) on the RECOLA dataset to estimate emotional attributes. Then, we integrate the estimated emotional attributes and the high-level representations from the CER-NET with the visual information to define the proposed affective video summarization architectures (AVSUM). In addition, we investigate the use of attention to improve the AVSUM architectures and propose two new architectures based on temporal attention (TA-AVSUM) and spatial attention (SA-AVSUM). We conduct video summarization experiments on the TvSum database. The proposed AVSUM-GRU architecture with an early fusion of high level GRU embeddings and the temporal attention based TA-AVSUM architecture attain competitive video summarization performances by bringing strong performance improvements for the human-centric videos compared to the state-of-the-art in terms of F-score and self-defined face recall metrics.
July 27, 2021
Yonatan Bisk, Carnegie Mellon University
Instructions, Abstraction, and Theory-of-Mind
This talk focuses on an overview of our recent environments and benchmarks: ALFRED and ALFWorld for instruction following in embodied and abstract action spaces. The goal is to help move the community towards building agents that connect language to action and understand abstract plans. As we move towards systems which interact with the world, we also need to think about how they interact with other agents. I close with a discussion of our recent ICML paper on Theory-of-Mind agents.
July 13, 2021
Marjan Firouznia, Amirkabir University
Develop New Deep Learning/Machine Learning Models for Medical Image Analysis
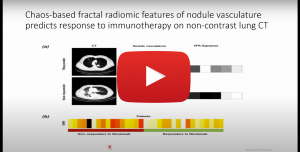
Biomedical image segmentation is an important tool for current clinical applications and basic research. The manual segmentation of medical images is a time-consuming, labor-intensive, and error-prone process. In Artificial Intelligence (AI), approaches inspired by mathematical models such as probability distribution mixture models and optimization theory have been employed to handle some main challenges in these areas. In this project we will propose new image segmentation methods for biomedical image analysis using deep learning models and fractal maps from CT scans. We will improve traditional image segmentation in 3D and deep learning models for CT/MRI scans. Also, we will apply the fractal features and Poincare maps to propose a new deep learning model for 3D segmentation using rich information of regions and voxels. The fractal analysis is used to represent shape and texture-based features to separate region interest from it surrounding. Then, we will apply Poincare maps to model the changes of boundaries to achieve a robust segmentation with high anatomical variations. Also, a novel machine learning (ML) method using a deep learning approach will be introduced for semantic segmentation of vessels, nodules, and myocardial walls using fractal maps. Multi-task fully convolutional networks (FCNs) will be constructed to improve the accuracy of semantic segmentation. These FCNs will learn the main task of semantic segmentation together with the auxiliary tasks of estimating the fractal maps.

July 6, 2021
Mustafa Akın Yılmaz, Koç University
End-to-End Rate-Distortion Optimization for Bi-Directional Learned Video Compression
Conventional video compression methods employ a linear transform and block motion model, and the steps of motion estimation, mode and quantization parameter selection, and entropy coding are optimized individually due to the combinatorial nature of the end-to-end optimization problem. Learned video compression allows end-to-end rate-distortion optimized training of all nonlinear modules, quantization parameter and entropy model simultaneously. Most of the works on learned video compression considered training a sequential video codec based on end-to-end optimization of cost averaged over pairs of successive frames. It is well-known in conventional video compression that hierarchical, bi-directional coding outperforms sequential compression because of its ability to selectively use reference frames from both future and past. To this effect, a hierarchical bi-directional learned lossy video compression system is presented in this thesis. Experimental results show that the rate-distortion performance of the proposed framework outperforms both traditional and other learned codecs in the literature yielding state-of-the art results.

Jun 29, 2021
Barbara Plank, IT University of Copenhagen
Learning with Scarce and Biased Data in Natural Language Processing
Transferring knowledge to solve a related problem and learning from scarce labeled data and unreliable biased inputs are examples of extraordinary human ability. State-of-the-art NLP models often fail under such conditions. In this talk, I will present some recent work to addresses these ubiquitous challenges. This includes work on cross-lingual learning for NLP, multi-task learning and learning from unreliable data.

Jun 22, 2021
Atil Iscen, Google Brain Robotics
Learning Legged Locomotion
Designing agile locomotion controllers for quadruped robots often requires extensive expertise and tedious manual tuning. Reinforcement Learning has shown success in solving many difficult control problems, and has potential to help with learning locomotion for physical robots. In this talk, I’ll present different methods we developed to tackle the locomotion problem using learning: Embedding prior knowledge, sim-to-real transfer, model-based reinforcement learning, hierarchical reinforcement learning, multi-task learning and using a mentor for harder tasks.

Jun 15, 2021
Jure Žbontar, Facebook AI Research
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow’s redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.

Jun 8, 2021
Fatma Güney, KUIS AI, Koç University
Structure, Motion, and Future Prediction in Dynamic Scenes
In this talk, I’ll talk about what we’ve been working on with Sadra and Kaan* in the last one and a half years in my group**. I’ll start by introducing the view synthesis approach to unsupervised monocular depth and ego-motion estimation by Zhou et al. [1]. I’ll point to its limitation with dynamic objects due to static background assumption and mention a few related works addressing it by conditioning on a given segmentation map. Then, I’ll introduce our approach to jointly reason about segmentation and depth without any conditioning. In the second part, I’ll introduce the stochastic video prediction framework proposed by Denton et al. [2] and show how we extend it to motion space with “SLAMP: Stochastic Latent Appearance and Motion Prediction”. Finally, I’ll talk about how structure and motion from the first part can help stochastic video prediction from the second part in real-world driving scenarios. [1] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe. Unsupervised learning of depth and ego-motion from video. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. [2] E. Denton and R. Fergus. Stochastic video generation with a learned prior. In Proc. of the International Conf. on Machine learning (ICML), 2018. *Also in collaboration with Aykut Erdem and Erkut Erdem. **Work under submission, please do not share.

Jun 1, 2021
Ömer Güneş, University of Oxford
Character Identification from Narrative Text
Having more than ten kinds of style; e.g. autobiography, fable, historical fiction, novel; narrative text constitutes an important part of written text. Despite the abundance of long-form textual data, it is not straightforward to develop robust natural language processing (NLP) models to understand narrative text automatically. Even for domain experts, analyzing and interpreting potentially long and complicated narrative (literary) texts to extract legible and concise information is a difficult process. Characters are among the most important aspects of a story. It is crucial to identify the characters of a narrative to understand that narrative deeply. Therefore, automatic character identification is a critical task in narrative natural language understanding. In this talk, we will provide a comprehensive overview of this new and exciting paradigm of character identification in the context of NLP and deep learning, and then we outline the major research challenges. We will also present our recent approach to automatically identifying characters from unannotated stories in natural language text, segmentation of conversations and attribution of utterances to characters for generating longform multi-voice audiobooks at scale.