Past AI Meetings

May 14, 2024
Danqi Chen, Princeton University
Data Selection for Pre-training and Instruction-tuning of LLMs
There is increasing evidence that choosing the right training data is essential for producing state-of-the-art large language models (LLMs). How can we decide on high-quality training data? Can we possibly select fewer data examples to improve performance and efficiency? In this talk, I will present two recent works on selecting high-quality data in pre-training and instruction tuning. I will first present QuRating, a simple framework for selecting pre-training data that captures the abstract attributes of texts humans intuitively perceive. We demonstrate that using state-of-the-art LLMs (e.g., GPT-3.5-turbo) can discern these qualities in pairwise judgments and emphasize the importance of balancing quality and diversity. We have created QuRatedPajama, a dataset comprising 260 billion tokens with fine-grained quality ratings, and show that sampling according to these ratings improves perplexity and in-context learning. Second, I present LESS, a method that effectively estimates data influences for identifying relevant instruction-tuning data for specific applications (a setting we call “targeted instruction tuning”). LESS is efficient, transferrable (we can use a smaller model for data selection), optimizer-aware (working with Adam), and easy to interpret. We show that training on a LESS-selected 5% of the data can often outperform training on full datasets on diverse downstream tasks.

May 09, 2024
Faïcel Chamroukh, Systemx, University of Caen, Lmno, Umr cns 6139
On Some Statistical and Machine Learning Problems in Research and Engineering
This talk will present a family of statistical (mixture of experts) distributions and ground their approximation and estimation properties related to their capabilities to deal with heterogenous data in high-dimensional and distributed/federated settings. It will also introduce approaches to leverage modern machine (deep) learning approaches with scientific and semantic knowledge to solve physical problems in engineering, including industrial design and supervision.

April 30, 2024
Murat Erdogdu, University of Toronto
Feature Learning in Two-layer Neural Networks: The Effect of Data Covariance
We study the effect of gradient-based optimization on feature learning in two-layer neural networks. We consider a setting where the number of samples is of the same order as the input dimension and show that, when the input data is isotropic, gradient descent always improves upon the initial random features model in terms of prediction risk, for a certain class of targets. Further leveraging the practical observation that data often contains additional structure, i.e., the input covariance has non-trivial alignment with the target, we prove that the class of learnable targets can be significantly extended, demonstrating a clear separation between kernel methods and two-layer neural networks in this regime.

March 26, 2024
Georg Martius, University of Tübingen
Machine Learning for Autonomously Learning Robots
I am driven by the question of how robots can autonomously develop skills to become versatile helpers for humans. Considering children, it seems natural that they have their own agenda. They playfully explore their environment, without the necessity for somebody to tell them exactly what to do next. Replicating such flexible learning in machines is highly challenging. I will present my research on different machine learning methods as steps towards solving this challenge. Part of my research is concerned with artificial intrinsic motivations — their mathematical formulation and embedding into learning systems. Equally important is to learn the right representations and internal models and I will show how powerful intrinsic motivations can be derived from learned models. With model-based reinforcement learning and planning methods, I show how we can achieve active exploration and playful robots but also safety aware behavior. A really fascinating feature is that these learning-by-playing systems are able to perform well in unseen tasks zero-shot.

March 19, 2024
Sebastian Risi, IT University of Copenhagen
Growing Adaptive and Self-Assembling Machines
Despite all their recent advances, current AI methods are often still brittle and fail when confronted with unexpected situations. By incorporating collective intelligence ideas, we have recently been able to create neural networks that self-organize their weights for fast adaptation, machines that can recognize their own shape, and machines that self-assemble through local interactions alone. Additionally, in this talk I will present initial results from my GROW-AI ERC project, where we are developing neural networks that grow through a developmental process that mirrors key properties of embryonic development in biological organisms. The talk concludes with future research opportunities and challenges that we need to address to best capitalize on the same ideas that allowed biological intelligence to strive.

March 12, 2024
Ahmet Üstün, Cohere For AI
Aya: An Open Science Initiative to Accelerate Multilingual AI Progress
Access to cutting-edge breakthroughs in large language models (LLMs) has been limited to speakers of only a few, primarily English, languages. The Aya project aimed to change that by focusing on accelerating multilingual AI through an open-source initiative. This initiative resulted in a state-of-the-art multilingual instruction-tuned model and the largest multilingual instruction collection. Built by 3,000 independent researchers across 119 countries, the Aya collection is the largest of its kind, crafted through templating and translating existing NLP datasets across 114 languages. As part of this collection, the Aya dataset is the largest collection of original annotations from native speakers worldwide, covering 65 languages. Finally, trained on a diverse set of instruction mixtures, including the Aya collection and dataset, the Aya model is a multilingual language model that can follow instructions in 101 languages, achieving state-of-the-art performance in various multilingual benchmarks.

March 05, 2024
Preslav Nakov, Mohamed bin Zayed University of Artificial Intelligence
Factuality Challenges in the Era of Large Language Models
We will discuss the risks, the challenges, and the opportunities that Large Language Models (LLMs) bring regarding factuality. We will then delve into our recent work on using LLMs to assist fact-checking (e.g., claim normalization, stance detection, question-guided fact-checking, program-guided reasoning, and synthetic data generation for fake news and propaganda identification), on checking and correcting the output of LLMs, on detecting machine-generated text (blackbox and whitebox), and on fighting the ongoing misinformation pollution with LLMs. Finally, we will discuss work on safeguarding LLMs, and the safety mechanisms we incorporated in Jais-chat, the world’s best open Arabic-centric foundation and instruction-tuned LLM.

February 27, 2024
Berk Canberk, Edinburgh Napier University
Real-Time Digital Twin System in 6G Era
With the tremendous advances in the upcoming 6G era, the world enters an age of connected intelligence. This will enable real-time Digital Twin deployments with specific integrated features such as seamless automation and control, augmented reality/virtual reality, visualization, and more connected devices per square kilometer. This new knowledge-based era of the 6G vision needs seamless control systems, fully automated management, artificial-intelligence enabled communication, well-bred computing methodologies, self-organizing behaviors, and high-end connectivity. Here, the importance of Digital Twins (DT) based systems has become vital. Digital Twin (DT) is the virtual representation of a Cyber-Physical System’s network elements and dynamics. The use of DT provides undue advantages such as resiliency, sustainability, real-time monitoring, control-tower-based management, thorough what-if analyses, an extremely high-performance simulation model for research, testing, and optimization. With these in mind, in this talk, first, a short recap of the ai-enabled digital twin concept and its potential market size in Industry 4.0 will be introduced. The technology behind DT, such as the high precision virtual network modeling and edge intelligence for ultra-low latency, will then be described. The reliability, latency, capacity, and connectivity issues in DT will be discussed. Moreover, several application areas of DT will also be underlined in terms of demand forecasting, warehouse automation, predictive maintenance, anomaly detection, risk assessment, intelligent scheduling, and control tower. Some important implementation areas of DT such as Supply Chain Management, Smart Manufacturing, Sustainable Product Line Management, Healthcare, and Smart Cities will also be covered.

January 23, 2024
Öznur Taştan, Sabancı University
Machine Learning for Life Sciences
In this talk, I will give examples of methods developed in our group at the intersection of machine learning and computational biology. The main body of the talk will focus on our drug synergy prediction efforts. Combination drug therapies are effective treatments for cancer. However, the genetic heterogeneity of the patients and exponentially large space of drug pairings pose significant challenges for finding the right combination for a specific patient. Current in silico prediction methods promise to reduce the vast number of candidate drug combinations for further screening. However, existing powerful methods are trained with cancer cell line gene expression data, which limits their applicability in clinical settings. While synergy measurements on cell lines models are available at large scale, patient-derived samples are too few to train a complex model. On the other hand, patient-specific single-drug response data are relatively more available. In this talk, I will first present our method trained on cell line gene expression data and further describe training strategies for customizing patient drug synergy predictions using single drug response data.

January 16, 2024
João Henriques, University of Oxford
A Light Touch Approach to Teaching Transformers Multi-view Geometry
Transformers are powerful visual learners, in large part due to their conspicuous lack of manually-specified priors. This flexibility can be problematic in tasks that involve multiple-view geometry, due to the near-infinite possible variations in 3D shapes and viewpoints (requiring flexibility), and the precise nature of projective geometry (obeying rigid laws). To resolve this conundrum, we propose a “light touch” approach, guiding visual Transformers to learn multiple-view geometry but allowing them to break free when needed. We achieve this by using epipolar lines to guide the Transformer’s cross-attention maps, penalizing attention values outside the epipolar lines and encouraging higher attention along these lines since they contain geometrically plausible matches. Unlike previous methods, our proposal does not require any camera pose information at test-time. We focus on pose-invariant object instance retrieval, where standard Transformer networks struggle, due to the large differences in viewpoint between query and retrieved images. Experimentally, our method outperforms state-of-the-art approaches at object retrieval, without needing pose information at test-time.

January 9, 2024
Hatice Köse, İstanbul Technical University
Affective Social Robots and Interaction Studies for Children with Disabilities
I will be summarizing our projects on the affective social humanoid robots for the education and health applications of children with disabilities. We develop affective modules to recognize the behaviours, attention, emotion and stress of children based on the data (physiological, facial, audio, an gaze) collected during their interaction with the robots and the sensory setup. We also work on the affect based serious games and exergames for children.

December 26, 2023
Tolga Birdal, Imperial College London
Topological Deep Learning: A New Hope for AI4Science
Topological deep learning is a rapidly growing field that pertains to the development of deep learning models for data supported on topological domains such as simplicial complexes, cell complexes, and hypergraphs, which generalize many domains encountered in scientific computations. In this talk, Tolga will present a unifying deep learning framework built upon an even richer data structure that includes widely adopted topological domains. Specifically, he will begin by introducing combinatorial complexes, a novel type of topological domain. Combinatorial complexes can be seen as generalizations of graphs that maintain certain desirable properties. Similar to hypergraphs, combinatorial complexes impose no constraints on the set of relations. In addition, combinatorial complexes permit the construction of hierarchical higher-order relations, analogous to those found in simplicial and cell complexes. Thus, combinatorial complexes generalize and combine useful traits of both hypergraphs and cell complexes, which have emerged as two promising abstractions that facilitate the generalization of graph neural networks to topological spaces. Second, building upon combinatorial complexes and their rich combinatorial and algebraic structure, Tolga will develop a general class of message-passing combinatorial complex neural networks (CCNNs), focusing primarily on attention-based CCNNs. He will additionally characterize permutation and orientation equivariances of CCNNs, and discuss pooling and unpooling operations within CCNNs. The performance of CCNNs on tasks related to mesh shape analysis and graph learning will be provided. The experiments demonstrate that CCNNs have competitive performance as compared to state-of-the-art deep learning models specifically tailored to the same tasks. These findings demonstrate the advantages of incorporating higher-order relations into deep learning models and shows great promise for AI4Science.

December 21, 2023
Dilara Keküllüoğlu, University of Edinburgh
Analysing User Behaviour and Assisting Users in Ever Advancing Technology
The rapidly changing technological landscape makes it difficult for people to understand the impacts of these advances and manage their boundaries. One such aspect is protecting user privacy in online social media platforms. People share a wide variety of information on social media, including personal and sensitive information, without understanding the size of their audience which may cause privacy complications. The networked nature of the platforms further exacerbates these complications where the information can be shared without the information owner’s control. People struggle to achieve their intended audience using the privacy settings provided by the platforms. Researching user behaviours in these situations is essential to understanding and helping people protect their privacy. Another domain where technological advances trouble people is the increasing use of artificial intelligence decisions in potentially harmful situations. The automated systems’ reasoning processes still often remain unclear to people interacting with such systems, which may also harm people by making unjust decisions. There are no efficient means for people to challenge automated decisions and obtain proper restitution if necessary. It is imperative that people are given tools to understand and contest these automated decisions easily.

December 12, 2023
Maciej Best, ETH Zurich
Chains, Trees, and Graphs of Thoughts: Demystifying Structured-Enhanced Prompting
The field of natural language processing has witnessed significant progress in recent years, with a notable focus on improving language models’ performance through innovative prompting techniques. Among these, structure-enhanced prompting has emerged as a promising paradigm, with designs such as Chain-of-Thought (CoT) or Tree of Thoughts (ToT), in which the LLM reasoning is guided by a structure such as a tree. In the first part of the talk, we overview this recent field, focusing on fundamental classes of harnessed structures, the representations of these structures, algorithms executed with these structures, relationships to other parts of the generative AI pipeline such as knowledge bases, and others. Second, we introduce Graph of Thoughts (GoT): a framework that advances prompting capabilities in LLMs beyond those offered by CoT or ToT. The key idea and primary advantage of GoT is the ability to model the information generated by an LLM as an arbitrary graph, where units of information (“LLM thoughts”) are vertices, and edges correspond to dependencies between these vertices. This approach enables combining arbitrary LLM thoughts into synergistic outcomes, distilling the essence of whole networks of thoughts, or enhancing thoughts using feedback loops. We illustrate that GoT offers advantages over state of the art on different tasks such as keyword counting while simultaneously reducing costs. We finalize with outlining research challenges in this fast-growing field.

December 5, 2023
Noah Snavely, Cornell University and Google Research
Modeling 3D Shape and Motion from Video
Computer vision and machine learning methods are getting really good at 3D reconstruction from 2D images. What they are not as good at is understanding, reconstructing, and generating scenes that are in motion. I’ll talk about recent work on new methods and scene representations that reconstruct and generate scenes that unfold over time.

November 28, 2023
Georgia Chalvatzaki, TU Darmstadt
Interactive Robot Perception and Learning for Mobile Manipulation
The long-standing ambition for autonomous, intelligent service robots that are seamlessly integrated into our everyday environments is yet to become a reality. Humans develop comprehension of their embodiments by interpreting their actions within the world and acting reciprocally to perceive it —- the environment affects our actions, and our actions simultaneously affect our environment. Besides great advances in robotics and Artificial Intelligence (AI), e.g., through better hardware designs or algorithms incorporating advances in Deep Learning in robotics, we are still far from achieving robotic embodied intelligence. The challenge of attaining artificial embodied intelligence — intelligence that originates and evolves through an agent’s sensorimotor interaction with its environment — is a topic of substantial scientific investigation and is still an open challenge. In this talk, I will walk you through our recent research works for endowing robots with spatial intelligence through perception and interaction to coordinate and acquire skills that are necessary for their promising real-world applications. In particular, we will see how we can use robotic priors for learning to coordinate mobile manipulation robots, how neural representations can allow for learning policies and safe interactions, and, at the crux, how we can leverage those representations to allow the robot to understand and interact with a scene, or guide it to acquire more “information” while acting in a task-oriented manner.

November 14, 2023
Kyunghyun Cho, New York University
Beyond Test Accuracies for Studying Deep Neural Networks
Already in 2015, Leon Bottou discussed the prevalence and end of the training/test experimental paradigm in machine learning. The machine learning community has however continued to stick to this paradigm until now (2023), relying almost entirely and exclusively on the test-set accuracy, which is a rough proxy to the true quality of a machine learning system we want to measure. There are however many aspects in building a machine learning system that require more attention. Specifically, I will discuss three such aspects in this talk; (1) model assumption and construction, (2) optimization and (3) inference. For model assumption and construction, I will discuss our recent work on generative multitask learning and incidental correlation in multimodal learning. For optimization, I will talk about how we can systematically study and investigate learning trajectories. Finally for inference, I will lay out two consistencies that must be satisfied by a large-scale language model and demonstrate that most of the language models do not fully satisfy such consistencies.

November 7, 2023
Berfin Şimşek, New York University
Finite-Width Neural Networks: A Landscape Complexity Analysis
In this talk, I will present an average-case analysis of finite-width neural networks through permutation symmetry. First, I will give a new scaling law for the critical manifolds of finite-width neural networks derived from counting all partitions due to neuron splitting from an initial set of neurons. Considering the invariance of zero neuron addition, we derive the scaling law of the zero-loss manifolds that is exact for the population loss. In a simplified setting, a factor 2log2 of overparameterization guarantees that the zero-loss manifolds are the most numerous. Our complexity calculations show that the loss landscape of neural networks exhibits extreme non-convexity at the onset of overparameterization, which is tamed gradually with overparameterization, and it effectively vanishes for infinitely wide networks. Finally, based on the theory, we will propose an `Expand-Cluster’ algorithm for model identification in practice.

October 31, 2023
Edward Johns, Robot Learning Lab at Imperial College London
Images, Language, and Actions: The Three Ingredients of Robot Learning
Most of the major recent breakthroughs in AI have relied on training huge neural networks on huge amounts of data. But what about a breakthrough in real-world robotics? One of the challenges is that physical robotics data is very scarce, and very expensive to collect. To address this, my team and I have been developing very data-efficient methods for robots to learn new tasks through human demonstrations. Using these methods, we are now able to quickly teach robots a range of everyday tasks, such as hammering in a nail, inserting a plug into a socket, and scooping up an object with a spatula. However, even with these efficient methods, providing human demonstrations can be laborious. Therefore, we have also been exploring the use of off-the-shelf neural networks trained on web-scale data, such as OpenAI’s DALL-E and GPT, to act as a robot’s “imagination” or its “internal monologue” when solving new tasks. Through this talk, we will explore the importance of image, language, and action data in robotics, as the three ingredients for scalable robot learning.

October 17, 2023
Petar Velickovic from Google DeepMind
Decoupling The Input Graph and The Computational Graph: The Most Important Unsolved Problem in Graph Representation Learning
When deploying graph neural networks, we often make a seemingly innocent assumption: that the input graph we are given is the ground-truth. However, as my talk will unpack, this is often not the case: even when the graphs are perfectly correct, they may be severely suboptimal for completing the task at hand. This will introduce us to a rich and vibrant area of graph rewiring, which is experiencing a renaissance in recent times. I will discuss some of the most representative works, including two of our own contributions (https://arxiv.org/abs/2210.02997, https://arxiv.org/abs/2306.03589), one of which won the Best Paper Award at the Graph Learning Frontiers Workshop at NeurIPS’22.

October 10, 2023
Eunsol Choi, University of Texas at Austin
Knowledge Augmentation for Language Models
Modern language models have the capacity to store and use immense amounts of knowledge about real world. Yet, their knowledge about the world is often incorrect or outdated, motivating ways to augment their knowledge. In this talk, I will present two complementary avenues for knowledge augmentation: (1) a modular, retrieval-based approach which brings in new information at inference time and (2) a parameter updating approach which aims to enable models to internalize new information and make inferences based on it.

August 14, 2023
Maks Ovsjanikov, École Polytechnique
Efficient and Robust Learning on Non-Rigid Surfaces and Graphs
In this talk, I will describe several approaches for learning on curved surfaces undergoing non-rigid deformations. First, I will give a brief overview of intrinsic convolution methods, and then present a different approach based on learned diffusion. The key properties of this approach are its robustness to changes in discretization and efficiency in enabling long-range communication, both in terms of memory and time. I will then showcase several applications, ranging from RNA surface segmentation to non-rigid shape correspondence, and present a recent extension for learning on graphs.

July 18, 2023
Hwee Kuan Lee, A*STAR Singapore
AI Driven Molecular Simulations
Accurate simulations of molecules play an important role in material design, drug discovery and industrial chemical processing. In the field of condensed matter physics, molecular simulations enable us to understand critical phenomena. However simulations of molecules at a large scale using conventional differential equation integrators is limited by the long simulation times. For example, at current, we are off my about 2 orders of magnitude in time scale for protein simulations. In this seminar, we will discuss several techniques of using Deep Neural Networks to learn the dynamics of molecules and hence circumvent the need for integrating equations of motions. Deep Learning techniques can generally speed up simulations by 10x to 100x while maintaining accuracies.

May 4, 2023
Yi-Zhe Song, University of Surrey
“Sketching” into the future of AI
Humans sketch, from historic times in caves, to the time being by scribbling on phones and tablets. As Artificial Intelligence (AI) learns to see and perceive the world around us (aka computer vision), understanding how humans sketch plays an important and fundamental role in casting insights into the human visual system, and in turn informing AI model designs. This talk is all about sketches, summarising over a decade of research from the SketchX Research Lab at the University of Surrey. By the end, it hopes to convey how sketch research can inform the future of AI, both in terms of fundamental theory and applications that could revolutionise the status quo.

May 2, 2023
Jacob Andreas, MIT
Language Models as World Models
The extent to which language modeling induces representations of the world outside text—and the broader question of whether it is possible to learn about meaning from text alone—have remained a subject of ongoing debate across NLP and cognitive sciences. I’ll present two studies from my lab showing that transformer language models encode structured and manipulable models of situations in their hidden representations. I’ll begin by presenting evidence from *semantic probing* indicating that LM representations of entity mentions encode information about entities’ dynamic state, and that these state representations are causally implicated downstream language generation. Despite this, even today’s largest LMs are prone to glaring semantic errors: they hallucinate facts, contradict input text, or even their own previous outputs. Building on our understanding of how LMs build models of entities and events, I’ll present a *representation editing* model called REMEDI that can correct these errors directly in an LM’s representation space, in some cases making it possible to generate output that cannot be produced with a corresponding textual prompt, and to detect incorrect or incoherent output before it is generated.

April 4, 2023
Anna Ivanova (MIT) & Kyle Mahowald (UT at Austin)
The Difference between Language and Thought
Today’s large language models (LLMs) routinely generate coherent, grammatical and seemingly meaningful paragraphs of text. This achievement has led to speculation that these models are—or will soon become—“thinking machines”, capable of performing tasks that require abstract knowledge and reasoning. In this talk, I will argue that, when evaluating LLMs, we should distinguish between their formal linguistic competence—knowledge of linguistic rules and patterns—and functional linguistic competence—understanding and using language in the world. This distinction stems from modern neuroscience research, which shows that these skills recruit different mechanisms in the human brain. I will show that, although LLMs are close to mastering formal linguistic competence, they still fail at many functional competence tasks, which require drawing on various non-linguistic cognitive skills. Finally, I will discuss why we humans are so tempted to mistake fluent speech for fluent thought.

March 21, 2023
Peter Dueben from European Centre for Medium Range Weather Forecasts (ECMWF)
Machine Learning for Weather and Climate Prediction
This talk will provide an overview on the state-of-the-art in machine learning in Earth system science. It will outline how conventional weather and climate models and machine learned models will co-exist in the future, and the challenges that need to be addressed when building the best machine learning forecast systems.t behavior in air combat.

March 14, 2023
Nazım Kemal Üre, ITU
Reinforcement Learning for Solving High Complexity Decision-Making Problems
Reinforcement learning (RL) has attracted significant interest in both academia and industry in recent years. The main premise of RL is the ability to control a system efficiently, without requiring any prior knowledge of the dynamics of the system. That being said, using RL as an out of the box approach only works for relatively simple problems with well-defined episodic structures, small number of actions and dense reward signals. On the other hand, many real-world problems possess extremely delayed reward signals, gigantic action spaces and non-episodic dynamics. In this talk, we will show that such high complexity decision making problems can be solved by wrapping RL algorithms with other powerful machine learning techniques, such as curriculum learning, hierarchical decompositions and imitation learning. We will demonstrate the potential of these methods across three different use cases; i) autonomous driving in urban environments, ii) playing real-time strategy games and iii) cloning fighter pilot behavior in air combat.

Feb 28, 2023
Iryna Gurevych, TU Darmstadt
InterText: Modelling Text as a Living Object in Cross-Document Context
Digital texts are cheap to produce, fast to update, easy to interlink, and there are a lot of them. The ability to aggregate and critically assess information from connected, evolving texts is at the core of most intellectual work – from education to business and policy-making. Yet, humans are not very good at handling large amounts of text. And while modern language models do a good job at finding documents, extracting information from them and generating natural-sounding language, the progress in helping humans read, connect, and make sense of interrelated texts has been very much limited.Funded by the European Research Council, the InterText project brings natural language processing (NLP) forward by developing a general framework for modelling and analysing fine-grained relationships between texts – intertextual relationships. This crucial milestone for AI would allow tracing the origin and evolution of texts and ideas and enable a new generation of AI applications for text work and critical reading. Using scientific peer review as a prototypical model of collaborative knowledge construction anchored in text, this talk will present the foundations of our intertextual approach to NLP, from data modelling and representation learning to task design, practical applications and intricacies of data collection. We will discuss the limitations of the state of the art, report on our latest findings and outline the open challenges on the path towards general-purpose AI for fine-grained cross-document analysis of texts.

Jan 19 2022
Emre Uğur, Boğaziçi University
DeepSym: An (Almost) End-to-End Symbol Extraction and Rule Learning System for Long-Horizon Robotic Planning
Symbolic planning and reasoning are powerful tools for robots tackling complex tasks. However, the need to manually design the symbols restrict their applicability, especially for robots that are expected to act in open-ended environments. Therefore symbol formation and rule extraction should be considered part of robot learning, which, when done properly, will offer scalability, flexibility, and robustness. Towards this goal, we propose a novel general method that finds action-grounded, discrete object and effect categories and builds probabilistic rules over them for non-trivial action planning.

Jan 10, 2022
Ali Afşin Bülbül, META
How to Avoid Pitfalls in Applied Data Science / Machine Learning Projects – Lessons Learnt the Hard Way
The path for a successful applied machine learning project is full of potholes. An ML practitioner will need to fall into these potholes and eventually gain their own experience, derive their own list of lessons-learnt. In this talk, I’ll share my experience in case it might help others avoid some of those pitfalls. Most failed ML projects fail because they attempt to solve a non-important, non-solvable or already solved problem. Taking the time, before writing the first line of code, and working with the stakeholders side-by-side to clarify the business problem, contratints, scope, roles and responsibilities is critical for the success of the project. I’ll talk about how a typical ML project team is structured and works together to deliver impact. During the execution of the project, there are certain best practices that will help the ML practitioner to avoid technical debts. In this talk, I try to define different types and sources of technical debts and some practical tips that could help avoiding or at least minimizing them.

Jan 3, 2022
Başak Tosun & Zafer Batık, Wikimedia Türkiye
Beyond Wikipedia: Wikimedia Movement and Sister Projects
As internet users, we all are using or being exposed to the content of Wikimedia projects in our daily lives. The content in Wikimedia projects is also useful as a dataset in advancing artificial intelligence research and application. In this talk we will be presenting Wikipedia and its sister projects from an editor-perspective, introduce the global movement behind those projects and give short information about the Lexicographical data project of Wikidata.

Dec 27, 2022
Serdar Özsoy & Shadi Hamdan, KUIS AI Center, Koç University
Self-Supervised Learning with an Information Maximization Criterion
Self-supervised learning allows AI systems to learn effective representations from large amounts of data using tasks that do not require costly labeling. Mode collapse, i.e., the model producing identical representations for all inputs, is a central problem to many self-supervised learning approaches, making self-supervised tasks, such as matching distorted variants of the inputs, ineffective. In this article, we argue that a straightforward application of information maximization among alternative latent representations of the same input naturally solves the collapse problem and achieves competitive empirical results. We propose a self-supervised learning method, CorInfoMax, that uses a second-order statistics-based mutual information measure that reflects the level of correlation among its arguments. Maximizing this correlative information measure between alternative representations of the same input serves two purposes: (1) it avoids the collapse problem by generating feature vectors with non-degenerate covariances; (2) it establishes relevance among alternative representations by increasing the linear dependence among them. An approximation of the proposed information maximization objective simplifies to a Euclidean distance-based objective function regularized by the log- determinant of the feature covariance matrix. The regularization term acts as a natural barrier against feature space degeneracy. Consequently, beyond avoiding complete output collapse to a single point, the proposed approach also prevents dimensional collapse by encouraging the spread of information across the whole feature space. Numerical experiments demonstrate that CorInfoMax achieves better or competitive performance results relative to the state-of-the-art SSL approaches.

Dec 22, 2022
İnanç Birol, University of British Columbia (UBC)
Mining Genomic Resources for Antimicrobial Peptides
The silent pandemic due to superbugs – pathogens resistant to multiple antimicrobial drugs – kills 1.5 million people every year. Threat from superbugs will only grow if the current practice of wide antibiotics use continues, and if we do not develop new alternatives to replace the ineffective drugs on the market. To fight this trend, drug development efforts are increasingly focusing on members of a certain biomolecule family called antimicrobial peptides (AMPs). These biomolecules have evolved together with the bacteria in their environment, and are known not to induce resistance to the same extent the conventional antibiotics do.
AMPs are employed by all classes of life, and their sequences are encoded in the species’ genomes. There is a rich repertoire of genomics data waiting to be mined to discover AMPs. In this presentation, I will describe the sequencing, bioinformatics, and testing technologies required to discover and validate AMPs in high throughput. Special emphasis will be on de novo sequence assembly methods and machine learning models for sequence annotation.

Dec 13, 2022
Desmond Elliott, University of Copenhagen
The End of Words? Language Modelling with Pixels
Language models are defined over a finite set of inputs, which creates a bottleneck if we attempt to scale the number of languages supported by a model. Tackling this bottleneck usually results in a trade-off between what can be represented in the embedding matrix and computational issues in the output layer. I will present PIXEL, the Pixel-based Encoder of Language, which suffers from neither of these issues. PIXEL is a pretrained language model that renders text as images, making it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels. PIXEL is trained on predominantly English data in the Wikipedia and Bookcorpus datasets to reconstruct the pixels of masked patches instead of predicting a probability distribution over tokens. I will present the results of an 86M parameter model on downstream syntactic and semantic tasks in 32 typologically diverse languages across 14 scripts. PIXEL substantially outperforms BERT when the script is not seen in the pretraining data but it lags behind BERT when working with Latin scripts. I will finish by showing that PIXEL is robust to noisy text inputs, further confirming the benefits of modelling language with pixels.

Dec 6, 2022
Jacob Chakareski, New Jersey Institute for Technology
NextG Wireless Systems at the Nexus of ML, Mobile XR, and UAV-IoT
The talk reflects the recent paradigm shift in wireless networks research from the traditional objective of enabling ever higher transmission rates at the physical layer to enabling for the network system higher resilience to attacks, higher robustness to system components’ failures, closer vertical integration with key emerging applications and their quality of experience needs, and intelligent self-coordination. The talk will comprise three stories of related recent research (the number three is good ). I will first talk about multi-connectivity enabled NextG wireless multi-user VR systems. Then, I will outline our advances in domain-aware fast RL for IoT systems. Third, I will talk about enabling real-time human AR streaming in NextG classrooms featuring real and virtual participants. The presentation of each of these studies will comprise a brief outline of the overall NSF project in which they are embedded. Next, I will highlight an interdisciplinary NIH R01 study I lead at the nexus of VR and AI aimed at addressing the societal need of low-vision rehabilitation. Finally, I will leave the floor open for questions and discussions.

Dec 1, 2022
Ekin Akyürek, Massachusetts Institute of Technology (MIT)
What Learning Algorithm Is In-Context Learning? Investigations with Linear Models
Neural sequence models, especially transformers, exhibit a remarkable capacity for in-context learning. They can construct new predictors from sequences of labeled examples (x, f(x)) presented in the input without further parameter updates. We investigate the hypothesis that transformer-based in-context learners implement standard learning algorithms implicitly, by encoding smaller models in their activations, and updating these implicit models as new examples appear in the context. Using linear regression as a prototypical problem, we offer three sources of evidence for this hypothesis. First, we prove by construction that transformers can implement learning algorithms for linear models based on gradient descent and closed-form ridge regression. Second, we show that trained in-context learners closely match the predictors computed by gradient descent, ridge regression, and exact least-squares regression, transitioning between different predictors as transformer depth and dataset noise vary, and converging to Bayesian estimators for large widths and depths. Third, we present preliminary evidence that in-context learners share algorithmic features with these predictors: learners’ late layers non-linearly encode weight vectors and moment matrices. These results suggest that in-context learning is understandable in algorithmic terms, and that (at least in the linear case) learners may rediscover standard estimation algorithms. Code and reference implementations released at this http link.

Nov 24, 2022
Utku Günay Acer, Nokia Bell Labs
The City Answers Your Questions: Sensory Intelligence at the Edge
This talk presents SensiX, a multi-tenant runtime for adaptive model execution with integrated MLOps on edge devices, e.g., a camera, a microphone, or IoT sensors. Through its highly modular componentisation to externalise data operations with clear abstractions and document-centric manifestation for system-wide orchestration, SensiX can serve multiple models efficiently with fine-grained control on edge devices while minimising data operation redundancy, managing data and device heterogeneity, reducing resource contention and removing manual MLOps.
A particular deployment of SensiX is an urban conversational agent. Lingo is a hyper-local conversational agent embedded deeply into the urban infrastructure that provides rich, purposeful, detailed, and in some cases, playful information relevant to a neighbourhood. Lingo provides hyper-local responses to user queries. The responses are computed by SensiX to act as an information source. These queries are served through a covert communication mechanism over Wi-Fi management frames to enable privacy-preserving proxemic interactions.

Nov 8, 2022
Chi-Chun Lee (Jeremy) ,National Tsing Hua University
Affective Speech Modeling and Analysis: Robustness, Generalization, Usability
Speech technology has proliferated into our life, and speech emotion recognition (SER) modules add humaine aspect to the wide-spread use of speech based services. Deep learning techniques play a key role in realizing SER for into-life application. In this talk, we will talk briefly about three main components of using deep models for SER: robustness, generalization and usability, and share several of our recent developments in each of the three main components.

Nov 1, 2022
Mehmet Esat Belviranli, Colorado School of Mines
Multi-Accelerator Execution of Neural Network Inference on Diversely Heterogeneous SoCs
Computing systems are becoming more complex by integrating specialized processing units, i.e., accelerators, that are optimized to perform a specific type of operation. This demand is fueled by the need to run distinct workloads in mobile and autonomous platforms. Such systems often embed diversely heterogeneous System-on-Chips(SoC) where an operation can be executed by more than a single type of accelerator with varying performance, energy, and latency characteristics. A hybrid (i.e., multi-accelerator) execution of popular workloads, such as neural network (NN) inference, collaboratively and concurrently on different types of accelerators in a diversely heterogeneous SoC is a relatively new and unexplored scheme. Multi-accelerator execution has the potential to provide unique benefits for computing systems with limited resources. In this talk, we investigate a framework that enables resource-constraint aware multi-accelerator execution for diversely heterogeneous SoCs. We achieve this by distributing the layers of a NN inference across different accelerators so that the trade-off between performance and energy satisfies system constraints. We further explore improving total throughput by concurrently using different types of accelerators for executing NNs in parallel. Our proposed methodology uniquely considers inter-accelerator transition costs, shared-memory contention and accelerator architectures that embed internal hardware pipelines. We employ empirical performance models and constraint-based optimization problems to determine optimal multi-accelerator execution schedules.

Oct 25, 2022
Erol Şahin, METU-ROMER (Center for Robotics and AI)
Imbuing Collaborative Robotic Manipulators with Human-Robot Interaction Skills
Industrial robots, a shining example of the success of robotics in the manufacturing domain, are developed as manipulators without any support for human-robot interaction (HRI). However, a new generation of manipulators, called Collaborative robots (Cobots), designed with embedded safety features, are being deployed to operate alongside humans. These advances are pushing HRI research, most of which is being conducted on “toy robots that do not do much work,” towards deployment on Cobots. In our two TUBITAK projects, called CIRAK and KALFA, we study how Cobots can be imbued with HRI capabilities in a collaborative assembly task. Based on the observation that manipulation skills of Cobots being (and will remain in the near future) inferior to the skill of workers, we envision Cobots positioning themselves as unskilled coworkers (hence the name CIRAK and KALFA) in which they hand in proper tools and parts to the worker. Within this talk, I will summarize our work towards imbuing HRI skills on Cobots through the use of some animation principles through behaviors such as “breathing” and “gazing”, as well as automatic assembly learning. Finally, I will briefly share the developments about METU-ROMER.

Oct 18, 2022
Mehmet Doğar, University of Leeds
Object Manipulation with Physics-Based Models
I will give an overview of our work on robotic object manipulation. First, I will talk about physics-based planning. This refers to robot motion planners that use predictions about the motion of contacted objects. We have particularly been interested in developing such planners for cluttered scenes, where multiple objects might simultaneously move as a result of robot contact. Second, I will talk about a more conventional grasping-based problem, where a robot must manipulate an object for the application of external forceful operations on it. Imagine a robot holding and moving a wooden board for a human, while the human drills holes into the board and cuts parts of it. I will describe our efforts in developing a planner that addresses the geometric, force stability, and human-comfort constraints for such a system.

Oct 04, 2022
Zeyu Wang, Hong Kong University of Science and Technology
Enhancing the Creative Process in Digital Prototyping
Despite advances in computer-aided design (CAD) systems and video editing software, digital content creation for design, storytelling, and interactive experiences remains a challenging problem. This talk introduces a series of studies, techniques, and systems along three thrusts that engage creators more directly and enhance the user experience in authoring digital content. First, we present a drawing dataset and spatiotemporal analysis that provide insight into how people draw by comparing tracing, freehand drawing, and computer-generated approximations. We found a high degree of similarity in stroke placement and types of strokes used over time, which informs methods for customized stroke treatment and emulating drawing processes. We also propose a deep learning-based technique for line drawing synthesis from animated 3D models, where our learned style space and optimization-based embedding enable the generation of line drawing animations while allowing interactive user control across frames. Second, we demonstrate the importance of utilizing spatial context in the creative process in augmented reality (AR) through two tablet-based interfaces. DistanciAR enables designers to create site-specific AR experiences for remote environments using LiDAR capture and new authoring modes, such as Dollhouse and Peek. PointShopAR integrates point cloud capture and editing in a single AR workflow to help users quickly prototype design ideas in their spatial context. Our user studies show that LiDAR capture and the point cloud representation in these systems can make rapid AR prototyping more accessible and versatile. Last, we introduce two procedural methods to generate time-based media for visual communication and storytelling. AniCode supports authoring and on-the-fly consumption of personalized animations in a network-free environment via a printed code. CHER-Ob generates video flythroughs for storytelling from annotated heterogeneous 2D and 3D data for cultural heritage. Our user studies show that these methods can benefit the video-oriented digital prototyping experience and facilitate the dissemination of creative and cultural ideas.

Facets of Efficiency in NLP
In recent years model sizes have increased substantially, and so did the cost for training them. This is problematic for two reasons: 1) it excludes organizations that do not have thousands of GPUs at hand for training such models, and 2) it becomes apparent that the hardware will not able to scale along with the growth of the models. Both can be alleviated by improving the efficiency of NLP models. This talk will first provide an overview of where efficiency may be improved within a typical NLP pipeline. We will then have a closer look at methods that improve data efficiency. Finally, we will discuss how we can quantify efficiency using different kinds of metrics.

Computational Imaging: Integrating Physical and Learned Models using Plug-and-Play Methods
Computational imaging is a rapidly growing area that seeks to enhance the capabilities of imaging instruments by viewing imaging as an inverse problem. Plug-and-Play Priors (PnP) is one of the most popular frameworks for solving computational imaging problems through the integration of physical and learned models. PnP leverages high-fidelity physical sensor models and powerful machine learning methods to provide state-of-the-art imaging algorithms. PnP algorithms alternate between minimizing a data-fidelity term to promote data consistency and imposing a learned regularizer in the form of an “artifact-reducing” deep neural network. Recent highly successful applications of PnP algorithms include bio-microscopy, computerized tomography, magnetic resonance imaging, and joint ptycho-tomography. This talk presents a unified and principled review of PnP by tracing its roots, describing its major variations, summarizing main results, and discussing applications in computational imaging.
May 24, 2022
Nils Reimers, Huggingface &TU Darmstadt
Advances in Neural Search
The advance of large pre-trained transformer models fundamentally changed Information Retrieval, resulting in substantially better search results without the need of large user-interaction data. In this talk, I will give an overview of different neural search techniques, their advantages and disadvantages, open challenges, and how they can successfully be used to improve any search system.
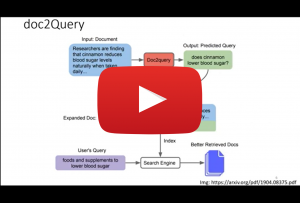
May 12, 2022
Ahmad P. Tafti, University of Southern Maine
Explainable AI in Medical Image Analysis: Lessons Learned in Total Joint Arthroplasty (TJA) Research
Orthopedic surgical procedures, and particularly total knee/hip arthroplasty (TKA/THA), are the most common and fastest growing surgeries in the United States. Almost 1.3 million TJA procedures occur on a yearly basis and more than 7 million Americans are currently living with artificial knee and/or hip joints. The widespread adoption of x-ray radiography and their availability at low cost, make them the principal method in assessing TJA and subtle TJA complications, such as osteolysis, implant loosening or infection over time, enabling surgeons to rule out complications and possible needs for revision surgeries. Rapid yet, with the growing number of TJA patients, the routine clinical and radiograph follow-up remain a daunting task for most orthopedic centers. It becomes an overwhelming amount of work, on a human scale, when we consider a radiologist or surgeon presented with the vast number of medical images daily. Smart computational strategies, such as explainable artificial intelligence and deep learning methods are thus required to analyze arthroplasty radiographs automatically and objectively, enabling both naive and experienced practitioners to perform radiographic follow-up with greater ease and speed, providing them with better explainability and interpretability in AI models. In this talk, we will be discussing the effectiveness of explainable AI methods to advance TJA research. We, together, will explore what explainable AI components do in TJA research and how.

May 10, 2022
Deniz Altınbüken, Google Brain Research
The Tip of the Iceberg: How to make ML for Systems work
Machine Learning has become a powerful tool to improve computer systems and there is a significant amount of research ongoing both in academia and industry to tackle systems problems using Machine Learning. Most work focuses on learning patterns and replacing heuristics with these learned patterns to solve systems problems such as compiler optimization, query optimization, failure detection, indexing, caching. However, solutions that truly improve systems need to maintain the efficiency, availability, reliability, and maintainability of systems while integrating Machine Learning into the system. In this talk, I will cover the key aspects and surprising joys of designing, implementing and deploying ML for Systems solutions based on my experiences of building and deploying these systems at Google.
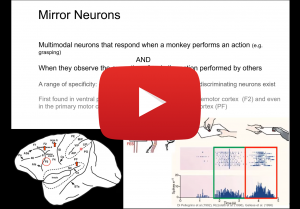
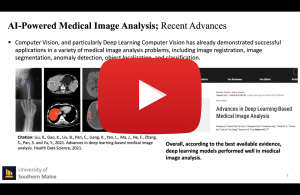
Apr 26, 2022
Erhan Öztop, Özyeğin University& Osaka University
Mirror Neurons from a Developmental Robotics Perspective
Mirror Neurons have been initially discovered in the ventral premotor cortex of macaque monkeys, which seem to represent action and perception in a common framework: they become active when a monkey executes a grasp action, as well as when the monkey observes another monkey or human perform a similar action. The computational modeling of the ‘mirror system’ makes a nice example of how developmental robotics interprets learning, which differs from the current supervised learning systems that can be trained with large, labeled data sets. In developmental robotics, learning data is mostly generated by the learning agent itself and is limited. When external information exists, severe restrictions exist as to what type of data is accessible to the agent. In this talk, I will present a pre-deep learning era mirror neuron modeling, followed by a new model that incorporates the state-of-the art deep neural networks. The latter work indicates that with developmentally valid constraints interesting behaviors may emerge even without feature engineering supporting the hypothesis that mirror neurons develop based on self-observation learning.
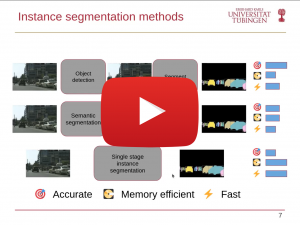
Apr 19, 2022
Nuri Benbarka, University of Tübingen
Instance Segmentation and 3D Multi-Object Tracking for Autonomous Driving
Autonomous driving promises to change the way we live. It could save lives, provide mobility, reduce wasted time driving, and enable new ways to design our cities. One crucial component in an autonomous driving system is perception, understanding the environment around the car to take proper driving commands. This talk will discuss two perception tasks: instance segmentation and 3D multi-object tracking. In instance segmentation, we discuss different mask representations and propose representing the mask’s boundary as Fourier series. We show that this implicit representation is compact, fast, and gives the highest mAP for a small number of parameters on the dataset MS COCO. Furthermore, during our work on instance segmentation, we found that the Fourier series is linked with the emerging field of implicit neural representations (INR). We show that the general form of the Fourier series is a Fourier mapped perceptron with integer frequencies. As a result, we know that one perceptron is enough to represent any signal if the Fourier mapping matrix has enough frequencies. In 3D MOT, we focus on tracklet management systems, classifying them into count-based and confidence-based systems. We found that the score update functions used previously for confidence-based systems are not optimal. Therefore, we propose better score update functions that give better score estimates. In addition, we used the same technique for the late fusion of object detectors. Finally, we tested our algorithm on the NuScenes and Waymo datasets, giving a consistent AMOTA boost.re given.

Mar 29, 2022
Prof. Dr. Björn Schuller, Imperial College London & University of Augsburg
Real Artificial Audio Intelligence: Computers Can Also Hear
We already got used to computers somewhat understanding our speech, and we can experience how well computers can already see, for example in autonomous vehicles. But can they also hear as good as we can or beyond? This talk introduces a new perspective on Computer Audition, by dissecting sounds into the individual sound sources and attributing them rich states and traits. Likewise, the sound of a cup put onto a desk becomes the sound sources “cup” and “desk” with attribution such as “the cup is made of china, has a crack, and seems half-full of liquid” or “the desk is made of pinewood and about 3 cm thick”, etc. As modelling such rich descriptions comes at tremendous data cravings, advances in self-supervised learning for audio as well as zero- and few-shot learning concepts are introduced among other data efficiency techniques. The talk shows a couple of first advances. Beyond, applications reaching from saving our health to saving our planet are given.

Mar 22, 2022
Ali Safaya, Koç University & Taner Sezer from Mersin University
Turkish Data Depository Project: Towards a Unified Turkish NLP Research Platform
The Turkish language has been left out of the state-of-the-art Natural Language Processing due to a lack of organized research communities. The lack of organized platforms makes it hard for foreign and junior researchers to contribute to Turkish NLP. We present the Turkish Data Depository (tdd.ai) project as a remedy for this. The main goal of TDD subprojects is collecting and organizing Turkish Natural Language Processing (NLP) datasets and providing a research basis for Turkish NLP. In this talk, I will present the results of our ongoing efforts to build TDD. I will go over our recently published user-friendly hub for Turkish NLP datasets (data.tdd.ai). Moreover, I will present our recently accepted ACL’22 paper on Mukayese (mukayese.tdd.ai), a benchmarking platform for various Turkish NLP tools and tasks, ranging from Spell-checking to Natural Language Understanding tasks (NLU).

Mar 8, 2022
Prof. Dr. Murat Tekalp, Koç University
State of The Art in Deep Learning for Image/Video Super-Resolution
Recent advances in neural architectures and training methods led to significant improvements in the performance of learned image/video restoration and SR. We can consider learned image restoration and SR as learning either a mapping from the space of degraded images to ideal images based on the universal approximation theorem or a generative model that captures the probability distribution of ideal images. An important benefit of data-driven deep learning approach is that neural models can be optimized for any differentiable loss function, including visual perceptual loss functions, leading to perceptual video restoration and SR, which cannot be easily handled by traditional model-based approaches. I will discuss loss functions and evaluation criteria for image/video restoration and SR, including fidelity and perceptual criteria, and the relation between them, where we briefly review the perception vs. fidelity (distortion) trade-off. We then discuss practical problems in applying supervised training to real-life restoration and SR, including overfitting image priors and overfitting the degradation model and some possible ways to deal with these problems.
Feb 22, 2022
Damla Övek & Zeynep Abalı, Koç University
Prediction of Protein-Protein Interactions Using Deep Learning
Proteins interact through their interfaces to fulfill essential functions in the cell. They bind to their partners in a highly specific manner and form complexes that have a profound effect on understanding the biological pathways they are involved in. Any abnormal interactions may cause diseases. As experimental data accumulates, artificial intelligence (AI) begins to be used and recent groundbreaking applications of AI profoundly impact the structural biology field. In this talk, we will discuss the deep learning methods applied for the prediction of protein-protein interactions and their interfaces.

Feb 15, 2022
Alper Erdoğan, Koç University
Polytopic Matrix Factorization and Information Maximization Based Unsupervised Learning
We introduce Polytopic Matrix Factorization (PMF) as a flexible unsupervised data decomposition approach. In this new framework, we model input data as unknown linear transformations of some latent vectors drawn from a polytope. The choice of polytope reflects the presumed features of the latent components and their mutual relationships. As the factorization criterion, we propose the determinant maximization (Det-Max) for the sample autocorrelation matrix of the latent vectors. We introduce a sufficient condition for identifiability, which requires that the convex hull of the latent vectors contains the maximum volume inscribed ellipsoid of the polytope with a particular tightness constraint. Based on the Det-Max criterion and the proposed identifiability condition, we show that all polytopes that satisfy a particular symmetry restriction qualify for the PMF framework. Having infinitely many polytope choices provides a form of flexibility in characterizing latent vectors. In particular, it is possible to define latent vectors with heterogeneous features, enabling the assignment of attributes such as nonnegativity and sparsity at the subvector level. We also propose an information-theoretic perspective for the determinant maximization-based matrix factorization frameworks. As further extensions, we will discuss the normative construction of neural networks based on local update rules.

Feb 10, 2022
Leyla Keser, İstanbul Bilgi University
Key Elements of the future legally binding instrument of the Council of Europe (CoE) Ad-Hoc Committee on AI (CAHAI)
The key elements of the CoE AI Convention, which will be the first Convention on AI in the world, have been prepared by an ad-hoc committee called CAHAI, which was established in 2019. CAHAI completed its mission with its last meeting on November 30-December 2, 2021, leaving behind a text detailing with the key elements that the binding international AI convention will come into force. In this event, this text prepared by CAHAI will be discussed with the participants explaining key elements regarding the entire lifecycle of AI.

Feb 8, 2022
Hooman Hedayati, University of North Carolina Chapel Hill
Improving Human-Robot Conversational Groups
This work aims to improve human-robot conversational groups, in which a robot is situated in an F-formation with humans. With a naive look, each robot consists of input devices e.g., sensors, cameras, etc. logic and decision-making blocks e.g., face detection algorithm, NLP, etc., and output devices e.g., actuators and speakers, etc. These components connect serially. Each component is prone to errors; therefore, each error feeds into the next component and decreases the overall efficiency of the system. For example, if the camera cannot see a person because of being obstructed by an object, then the human detection algorithm cannot detect that person and then the robot won’t consider that person in the interaction. These types of errors decrease the efficiency of the system and also negatively impact human-robot interaction. In this work, we propose four systems that aim to help understand human-robot conversational groups better, reason about them, find the mentioned errors and overcome them. First, we look at the difference between human-human conversational groups and human-robot conversation groups. Second, we propose an algorithm to detect conversational groups (F-formations). Third, we look at how to detect missing people in the conversational groups and validate human-detection algorithms. Last, we propose an algorithm to detect the active speaker based on visual cues and help robots behave normally in conversational groups.

Jan 26, 2022
Weights & Biases
ML Model Optimization with Weights & Biases
We had our very first tutorial talk!
Weights & Biases introduced their platform to monitor training of neural network models.
Jan 12, 2022
Raffaella Bernardi, University of Trento
Two Challenges Behind Visual Dialogues: Grounding Negation and Asking an Informative Question
Visual Dialogues are an intriguing challenge for the Computer Vision and Computational Linguistics communities. They involve both understanding multimodal inputs as well as generating visually grounded questions. We take the GuessWhat?! game as test-bed since it has a simple dialogue structure — Yes-No question answer asymmetric exchanges. We wonder to which extent State-Of-The-Art models take the answers into account and in particular whether they handle positively/negatively answered questions equally well. Moreover, the task is goal oriented: the questioner has to guess the target object in an image. As such it is well suited to study dialogue strategies. SOTA systems are shown to generate questions that, although grammatically correct, often lack an effective strategy and sound unnatural to humans. Inspired by the cognitive literature on information search and cross-situational word learning, we propose Confirm-it, a model based on a beam search re-ranking algorithm that guides an effective goal-oriented strategy by asking questions that confirm the model’s conjecture about the referent. We show that dialogues generated by Confirm-it are more natural and effective than beam search decoding without re-ranking. The work is based on the following publications: Alberto Testoni, Claudio Greco and Raffaella Bernardi Artificial Intelligence models do not ground negation, humans do. GuessWhat?! dialogues as a case study Front.ers in Big Data doi: 10.3389/fdata.2021.736709 Alberto Testoni, Raffaella Bernardi “Looking for Confirmations: An Effective and Human-Like Visual Dialogue Strategy”. In Proceedings of EMNLP 2021 (Short paper).
Jan 5, 2022
Ayşegül Dündar, Bilkent University
Controllable Image Synthesis
With GAN based models achieving realistic image synthesis on various objects, there has been an increased interest to deploy them for gaming, robotics, architectural designs, and AR/VR applications. However, such applications also require full controllability on the synthesis. To enable controllability, image synthesis has been conditioned on various inputs such as semantic maps, keypoints, and edges to name a few. With these methods, control and manipulation over generated images are still limited. In a new line of research, methods are proposed to learn 3D attributes from images for precise control on the rendering. In this talk, I will cover a range of image synthesis works, starting with conditional image synthesis and continue with 3D attributes learning from single view images for the aim of image synthesis.
Dec 29, 2021
Ayça Atabey, Bilgi IT Law and UN Women
An Interdisciplinary Look at Fairness in AI-driven Assistive Technologies: Mapping Value Sensitive Design (Human-Computer Interaction) onto Data Protection Principles
Value sensitive design (VSD) in Human-Computer Interaction is an established method for integrating values into technical design. Design of AI-driven technologies for vulnerable data subjects requires a particular attention to values such as transparency, fairness, and accountability. To achieve this, there is a need for an interdisciplinary look to the fairness principle in data protection law to bridge the gap between what the law requires and what happens in practice. This talk explores the interdisciplinary approach to Fairness in AI-driven Assistive Technologies through mapping VSD onto Data Protection rules.

Dec 22, 2021
Iacer Calixto, University of Amsterdam & New York University
VALSE : A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
I will talk about a recent collaborative work on VALSE (Vision And Language Structured Evaluation), a novel benchmark designed for testing general-purpose pretrained vision and language (V&L) models for their visio-linguistic grounding capabilities on specific linguistic phenomena. VALSE offers a suite of tests covering various linguistic constructs. Solving these requires models to ground linguistic phenomena in the visual modality, allowing more fine-grained evaluations than hitherto possible. We build VALSE using methods that support the construction of valid foils, and report results from evaluating five widely-used V&L models. Our experiments suggest that current models have considerable difficulty addressing most phenomena. Hence, we expect VALSE to serve as an important benchmark to measure future progress of pretrained V&L models from a linguistic perspective, complementing the canonical task centred V&L evaluations.
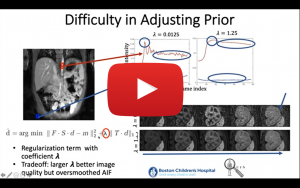
Dec 15, 2021
Sıla Kurugol, Harvard Medical School
Quantification of Clinically Useful Information from 3D and 4D MR Images: Computational and Deep Learning Techniques for Image Reconstruction, Motion Compensation and Quantitative Parameter Estimation
The talk will focus on the use of medical imaging, computational and deep learning techniques for the discovery and quantification of clinically useful information from 3D and 4D medical images. The talk will describe how computational techniques or deep learning methods can be used for the reconstruction of MR images from undersampled (limited) data for accelerated MR imaging, motion-compensated imaging and robust quantitative parameter estimation and image analysis. It will also show the clinical utility of these proposed techniques for the interpretation of medical images and extraction of important clinical markers in applications such as functional imaging of kidneys and Crohn’s disease.

Dec 1, 2021
Jan-Philipp Fränken, University of Edinburgh
Algorithms of Adaptation in Inductive Inference
We investigate the idea that human concept inference utilizes local incremental search within a compositional mental theory space. To explore this, we study judgments in a challenging task, where participants actively gather evidence about a symbolic rule governing the behavior of a simulated environment. Participants construct mini-experiments before making generalizations and explicit guesses about the hidden rule. They then collect additional evidence themselves (Experiment 1) or observe evidence gathered by someone else (Experiment 2) before revising their own generalizations and guesses. In each case, we focus on the relationship between participants’ initial and revised guesses about the hidden rule concept. We find an order effect whereby revised guesses are anchored to idiosyncratic elements of the earlier guesses. To explain this pattern, we develop a family of process accounts that combine program induction ideas with local (MCMC-like) adaptation mechanisms. A particularly local variant of this adaptive account captures participants’ revisions better than a range of alternatives. We take this as suggestive that people deal with the inherent complexity of concept inference partly through use of local adaptive search in a latent compositional theory space.
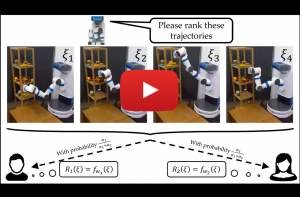
Nov 22, 2021
Erdem Bıyık, Stanford University
Learning Preferences for Interactive Autonomy
In human-robot interaction or more generally multi-agent systems, we often have decentralized agents that need to perform a task together. In such settings, it is crucial to have the ability to anticipate the actions of other agents. Without this ability, the agents are often doomed to perform very poorly. Humans are usually good at this, and it is mostly because we can have good estimates of what other agents are trying to do. We want to give such an ability to robots through reward learning and partner modeling. In this talk, I am going to talk about active learning approaches to this problem and how we can leverage preference data to learn objectives. I am going to show how preferences can help reward learning in the settings where demonstration data may fail, and how partner-modeling enables decentralized agents to cooperate efficiently.

Nov 3, 2021
Zaid Rassim Mohammed Al-Saadi, Koç Univesity
A Novel Haptic Feature Set for the Classification of Interactive Motor Behaviors in Collaborative Object Transfer
Haptics provides a natural and intuitive channel of communication during the interaction of two humans in complex physical tasks, such as joint object transportation. However, despite the utmost importance of touch in physical interactions, the use of haptics is under-represented when developing intelligent systems. This study explores the prominence of haptic data to extract information about underlying interaction patterns within physical human-human interaction (pHHI). We work on a joint object transportation scenario involving two human partners, and show that haptic features, based on force/torque information, suffice to identify human interactive behavior patterns. We categorize the interaction into four discrete behavior classes. These classes describe whether the partners work in harmony or face conflicts while jointly transporting an object through translational or rotational movements. In an experimental study, we collect data from 12 human dyads and verify the salience of haptic features by achieving a correct classification rate over 91% using a Random Forest classifier.

Oct 26, 2021
Laura Leal-Taixé from Technical University of Munich
Shifting Paradigms in Multi-Object Tracking
The challenging task of multi-object tracking (MOT) requires simultaneous reasoning about track initialization, identity, and spatiotemporal trajectories. This problem has been traditionally addressed with the tracking-dy-detection paradigm. In this talk, I will discuss more recent paradigms, most notably, tracking-by-regression, and the rise of a new paradigm: tracking-by-attention. In this new paradigm, we formulate MOT as a frame-to-frame set prediction problem and introduce TrackFormer, an end-to-end MOT approach based on an encoder-decoder Transformer architecture. Our model achieves data association between frames via attention by evolving a set of track predictions through a video sequence. The Transformer decoder initializes new tracks from static object queries and autoregressively follows existing tracks in space and time with the new concept of identity preserving track queries. Both decoder query types benefit from self- and encoder-decoder attention on global frame-level features, thereby omitting any additional graph optimization and matching or modeling of motion and appearance. At the end of the talk, I also want to discuss some of our work in collecting data for tracking with data privacy in mind.
Oct 21, 2021
Mustafa Ümit Öner from National University of Singapore
How strong are the weak labels in digital histopathology?
Histopathology is the golden standard in the clinic for cancer diagnosis and treatment planning. Recently, slide scanners have transformed histopathology into digital, where glass slides are digitized and stored as whole-slide-images (WSIs). WSIs provide us with precious data that powerful deep learning models can exploit. However, a WSI is a huge gigapixel image that traditional deep learning models cannot process. Besides, deep learning models require a lot of labeled data. Nevertheless, most WSIs are either unannotated or annotated with some weak labels indicating slide-level properties, like a tumor slide or a normal slide. This seminar will discuss our novel deep learning models tackling huge images and exploiting weak labels to reveal fine-level information within the images. Firstly, we developed a weakly supervised clustering framework. Given only the weak labels of whether an image contains metastases or not, this framework successfully segmented out breast cancer metastases in the lymph node sections. Secondly, we developed a deep learning model predicting tumor purity (percentage of cancer cells within a tissue section) from digital histopathology slides. Our model successfully predicted tumor purity in eight different TCGA cohorts and a local Singapore cohort. The predictions were highly consistent with genomic tumor purity values, which were inferred from genomic data and accepted as accurate for downstream analysis. Furthermore, our model provided tumor purity maps showing the spatial variation of tumor purity within sections, which can help better understand the tumor microenvironment.
Oct 20, 2021
Barret Zoph from Google Brain
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) models defy this and instead select different parameters for each incoming example. The result is a sparsely-activated model – with an outrageous number of parameters – but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs, and training instability. We address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques mitigate the instabilities, and we show large sparse models may be trained, for the first time, with lower precision formats. We design models based off T5-Base and T5-Large (Raffel et al., 2019) to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus”, and achieve a 4x speedup over the T5-XXL model.
Oct 12, 2021
Fatih Dinç, Stanford University
Uncovering The Neural Circuitry in The Brain Using Recurrent Neural Networks
The talk is structured in two parts. The first part focuses on the developments in recurrent neural network training algorithms over the years. We first identify the types of recurrent neural networks currently used in neuroscience research based on the training properties and target function. Here, we will discuss the seminal work by Sompolinsky and Crisanti from 1988 regarding chaos in random neural networks, the reservoir computing paradigm, back-propagation through time, and neural activation (not output) based training algorithms. In the second part, we will go through a selection of papers from neuroscience literature using these methods to uncover the neural circuitry in the brain. As machine learning and neuroscience literature have always inspired progress in each other, there is a high chance that some of these biological findings might have direct relevance in artificial neural network research. We will conclude with some candidate ideas.
Oct 6, 2021
Ali Hürriyetoğlu, Koç University
Challenging the Standards for Socio-Political Event Information Collection
Spatio-temporal distribution of socio-political events sheds light on the causes and effects of government policies and political discourses that resonate in society. Socio-political event data is utilized for national and international policy- and decision-making. Therefore, the reliability and validity of these datasets are of utmost importance. I will present a summary of my studies that examine common assumptions made during creating socio-political event databases such as GDELT and ICEWS. The assumptions I tackled have been 1) keyword filtering is an essential step for determining the documents that should be analyzed further, 2) a news report contains information about a single event, 3) sentences that are self-contained in terms of event information coverage are the majority, and 4) automated tool performance on new data is comparable to the performance on the validation setting. Moreover, I will present how my work brought the computer science and socio-political science communities together to quantify state-of-the-art automated tool performances on event information collection in cross-context and multilingual settings in the context of a shared task and workshop series, which are ProtestNews Lab @ CLEF 2019, COPE @ Euro CSS 2019, AESPEN @ LREC 2020, and CASE @ ACL 2021, I initiated.
Sep 28, 2021
Abdul Basit Anees and Ahmet Canberk Baykal, KUIS AI MSc Fellows
Text-Guided Image Manipulation Using GAN Inversion
Recent GAN models are capable of generating very high-quality images. Then, a very important follow-up problem is, how to control these generated images. A careful analysis of the latent space of GANs suggests that this control can be achieved by manipulating the latent codes in a desired direction. In this talk, we will be presenting our model that is capable of modifying images in such a way that they have some desired attributes corresponding to any text description. For this purpose, we use the idea of GAN inversion. Our model makes use of two encoders to invert the images along with their textual descriptions to the latent space of a pre-trained StyleGAN model. Additionally, we utilize OpenAI’s Contrastive Language-Image Pre-training (CLIP) model to enforce the latent codes to be aligned with the desired textual descriptions. The inverted latent codes are fed to the StyleGAN generator to obtain the manipulated images. We conducted experiments on face datasets and compared our results with the related work.

Sep 21, 2021
Cagatay Yildiz, Aalto University, Finland
Continuous-Time Model-Based Reinforcement Learning
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. Such discrete-time approximations typically lead to inaccurate dynamic models, which in turn deteriorate the control learning task. In this talk, I will describe an alternative continuous-time MBRL framework for RL. Our approach infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We also propose a novel continuous-time actor-critic algorithm for policy learning. Our experiments illustrate that the model is robust against irregular and noisy data, is sample-efficient, and can solve control problems which pose challenges to discrete-time MBRL methods.

Sep 14, 2021
Deqing Sun, Google Research
Learning Optical Flow: from Model to Data
Optical flow provides important motion information about the dynamic world and is of fundamental importance to many tasks. In this talk, I will discuss two different aspects of learning optical flow: model and data. I will start with the background and classical approach to optical flow. Next, I will talk about PWC-Net, a compact and effective model built using classical principles for optical flow. Finally, I will introduce AutoFlow, a simple and effective method to render training data for optical flow that optimizes the performance of a model on a target dataset.

Sep 7, 2021
Jordi Pont-Tuset, Google Research
Tightly Connecting Vision and Language: Localized Narratives and Beyond
Localized Narratives are a new form of multimodal image annotations connecting vision and language: annotators describe an image with their voice while simultaneously hovering their mouse over the region they are describing. Since the voice and the mouse pointer are synchronized, we can localize every single word in the description. Based on and inspired by this data, we first designed a new image retrieval modality by “speaking and pointing”, which comes naturally to humans and we show it works very well in practice. Second, we robustly matched the noun phrases in the captions to the panoptic categories in COCO to provide a dense pixel grounding. With this new data, we propose the new task of Panoptic Narrative Grounding and present a very solid baseline that, given an image caption, outputs a segmentation that grounds all their nouns.
August 17, 2021
Tunca Doğan, Hacettepe University
Development and Application of Data-Driven Approaches to Make Sense out of Large-Scale and Heterogeneous Biomolecular Data
The recent availability of inexpensive technologies led to a surge of biological/biomedical data production and accumulation in public servers. These noisy, complex and large-scale data should be analyzed in order to understand mechanisms that constitute life and to develop new and effective treatments against prevalent dieases. A key concept in this endeavour is the prediction of unknown attributes and properties of biomolecules (i.e., genes, proteins and RNAs) such as their molecular functions, physical interactions and etc., together with their relationships to high-level biomedical concepts such as systems and diseases. Lately, cutting-edge data-driven approaches are started to be applied to biological data to aid the development of novel and effective in silico solutions. In this seminar, I’ll summarize our efforts for integrating and representing heterogeneous data from different biological/biomedical data resources (i.e., the CROssBAR project) together with the development and application of deep learning-based computational methods for enriching the integrated data by predicting unknown functions and drug discovery centric ligand interactions of human genes and proteins. These tools and services are developed with the aim of helping researchers from diverse fields of the life-sciences domain in building and pre-evaluating their hypothesis, before planning and executing costly and risky experimental/clinical studies.

August 10, 2021
Ahsan Ali, Argonne National Lab, USA
Towards Scalable and Adaptive Machine Learning Design and Training
Machine-Learning-as-a-Service (MLaaS) aims to support the optimized execution of machine learning (ML) tasks on cloud infrastructure. Existing MLaaS systems are mainly built atop conventional VM- based architectures and suffer from slow scaling, are cost-inefficient, and require extensive domain expertise to optimize the training deployment and execution. Moreover, ML training tasks often have varying resource demands across different training phases, which adds to the complexity. To address these challenges, we propose SMLT, an automated, scalable, and adaptive framework to perform ML design and training on cloud infrastructure. By embracing the emerging serverless computing paradigm, SMLT provides flexibility and cost-efficiency. By employing a hierarchical model synchronization mechanism, SMLT addresses the challenge of poor inter-connections between serverless functions. In addition, we design an automated and adaptive scheduling mechanism to dynamically optimize the deployment and resource scaling for ML tasks during training. SMLT supports all major ML frameworks and is open-sourced. The experimental evaluation with large, sophisticated modern ML models demonstrates that SMLT outperforms the state-of-the-art MLaaS systems and existing serverless ML training frameworks in both performances (up to 8x) and monetary cost (up to 2x).
July 29, 2021
Berkay Köprü, Koc University
Use of Affective Visual Information for Summarization of Human-Centric Videos
Increasing volume of user-generated human-centric video content and their applications, such as video retrieval and browsing, require compact representations that are addressed by the video summarization literature. Current supervised studies formulate video summarization as a sequence-to-sequence learning problem and the existing solutions often neglect the surge of human-centric view, which inherently contains affective content. In this study, we investigate the affective-information enriched supervised video summarization task for human-centric videos. First, we train a visual input-driven state-of-the-art continuous emotion recognition model (CER-NET) on the RECOLA dataset to estimate emotional attributes. Then, we integrate the estimated emotional attributes and the high-level representations from the CER-NET with the visual information to define the proposed affective video summarization architectures (AVSUM). In addition, we investigate the use of attention to improve the AVSUM architectures and propose two new architectures based on temporal attention (TA-AVSUM) and spatial attention (SA-AVSUM). We conduct video summarization experiments on the TvSum database. The proposed AVSUM-GRU architecture with an early fusion of high level GRU embeddings and the temporal attention based TA-AVSUM architecture attain competitive video summarization performances by bringing strong performance improvements for the human-centric videos compared to the state-of-the-art in terms of F-score and self-defined face recall metrics.
July 27, 2021
Yonatan Bisk, Carnegie Mellon University
Instructions, Abstraction, and Theory-of-Mind
This talk focuses on an overview of our recent environments and benchmarks: ALFRED and ALFWorld for instruction following in embodied and abstract action spaces. The goal is to help move the community towards building agents that connect language to action and understand abstract plans. As we move towards systems which interact with the world, we also need to think about how they interact with other agents. I close with a discussion of our recent ICML paper on Theory-of-Mind agents.
July 13, 2021
Marjan Firouznia, Amirkabir University
Develop New Deep Learning/Machine Learning Models for Medical Image Analysis
Biomedical image segmentation is an important tool for current clinical applications and basic research. The manual segmentation of medical images is a time-consuming, labor-intensive, and error-prone process. In Artificial Intelligence (AI), approaches inspired by mathematical models such as probability distribution mixture models and optimization theory have been employed to handle some main challenges in these areas. In this project we will propose new image segmentation methods for biomedical image analysis using deep learning models and fractal maps from CT scans. We will improve traditional image segmentation in 3D and deep learning models for CT/MRI scans. Also, we will apply the fractal features and Poincare maps to propose a new deep learning model for 3D segmentation using rich information of regions and voxels. The fractal analysis is used to represent shape and texture-based features to separate region interest from it surrounding. Then, we will apply Poincare maps to model the changes of boundaries to achieve a robust segmentation with high anatomical variations. Also, a novel machine learning (ML) method using a deep learning approach will be introduced for semantic segmentation of vessels, nodules, and myocardial walls using fractal maps. Multi-task fully convolutional networks (FCNs) will be constructed to improve the accuracy of semantic segmentation. These FCNs will learn the main task of semantic segmentation together with the auxiliary tasks of estimating the fractal maps.

July 6, 2021
Mustafa Akın Yılmaz, Koç University
End-to-End Rate-Distortion Optimization for Bi-Directional Learned Video Compression
Conventional video compression methods employ a linear transform and block motion model, and the steps of motion estimation, mode and quantization parameter selection, and entropy coding are optimized individually due to the combinatorial nature of the end-to-end optimization problem. Learned video compression allows end-to-end rate-distortion optimized training of all nonlinear modules, quantization parameter and entropy model simultaneously. Most of the works on learned video compression considered training a sequential video codec based on end-to-end optimization of cost averaged over pairs of successive frames. It is well-known in conventional video compression that hierarchical, bi-directional coding outperforms sequential compression because of its ability to selectively use reference frames from both future and past. To this effect, a hierarchical bi-directional learned lossy video compression system is presented in this thesis. Experimental results show that the rate-distortion performance of the proposed framework outperforms both traditional and other learned codecs in the literature yielding state-of-the art results.

Jun 29, 2021
Barbara Plank, IT University of Copenhagen
Learning with Scarce and Biased Data in Natural Language Processing
Transferring knowledge to solve a related problem and learning from scarce labeled data and unreliable biased inputs are examples of extraordinary human ability. State-of-the-art NLP models often fail under such conditions. In this talk, I will present some recent work to addresses these ubiquitous challenges. This includes work on cross-lingual learning for NLP, multi-task learning and learning from unreliable data.

Jun 22, 2021
Atil Iscen, Google Brain Robotics
Learning Legged Locomotion
Designing agile locomotion controllers for quadruped robots often requires extensive expertise and tedious manual tuning. Reinforcement Learning has shown success in solving many difficult control problems, and has potential to help with learning locomotion for physical robots. In this talk, I’ll present different methods we developed to tackle the locomotion problem using learning: Embedding prior knowledge, sim-to-real transfer, model-based reinforcement learning, hierarchical reinforcement learning, multi-task learning and using a mentor for harder tasks.

Jun 15, 2021
Jure Žbontar, Facebook AI Research
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow’s redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.

Jun 8, 2021
Fatma Güney, KUIS AI, Koç University
Structure, Motion, and Future Prediction in Dynamic Scenes
In this talk, I’ll talk about what we’ve been working on with Sadra and Kaan* in the last one and a half years in my group**. I’ll start by introducing the view synthesis approach to unsupervised monocular depth and ego-motion estimation by Zhou et al. [1]. I’ll point to its limitation with dynamic objects due to static background assumption and mention a few related works addressing it by conditioning on a given segmentation map. Then, I’ll introduce our approach to jointly reason about segmentation and depth without any conditioning. In the second part, I’ll introduce the stochastic video prediction framework proposed by Denton et al. [2] and show how we extend it to motion space with “SLAMP: Stochastic Latent Appearance and Motion Prediction”. Finally, I’ll talk about how structure and motion from the first part can help stochastic video prediction from the second part in real-world driving scenarios. [1] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe. Unsupervised learning of depth and ego-motion from video. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. [2] E. Denton and R. Fergus. Stochastic video generation with a learned prior. In Proc. of the International Conf. on Machine learning (ICML), 2018. *Also in collaboration with Aykut Erdem and Erkut Erdem. **Work under submission, please do not share.

Jun 1, 2021
Ömer Güneş, University of Oxford
Character Identification from Narrative Text
Having more than ten kinds of style; e.g. autobiography, fable, historical fiction, novel; narrative text constitutes an important part of written text. Despite the abundance of long-form textual data, it is not straightforward to develop robust natural language processing (NLP) models to understand narrative text automatically. Even for domain experts, analyzing and interpreting potentially long and complicated narrative (literary) texts to extract legible and concise information is a difficult process. Characters are among the most important aspects of a story. It is crucial to identify the characters of a narrative to understand that narrative deeply. Therefore, automatic character identification is a critical task in narrative natural language understanding. In this talk, we will provide a comprehensive overview of this new and exciting paradigm of character identification in the context of NLP and deep learning, and then we outline the major research challenges. We will also present our recent approach to automatically identifying characters from unannotated stories in natural language text, segmentation of conversations and attribution of utterances to characters for generating longform multi-voice audiobooks at scale.

May 18, 2021
Cengiz Öztireli from Google Research, University of Cambridge
3D Digital Reality Modeling for Perception
Creating digital models of reality is one of the grand challenges of computer science. In this talk, I will summarize some of our efforts towards achieving this goal to allow machines to perceive the world as well as and beyond humans. The focus will be on capturing and replicating the visual world and techniques at the intersection of computer graphics, vision, and machine learning to solve several fundamental problems and their practical applications.
May 11, 2021
Sinan Öncü, Smart and Autonomous Mobility Research Laboratory, Boğaziçi University.
Cooperative Perception and Control for Autonomous Vehicles
This talk will be on past and currently ongoing research projects of Sinan Öncü on various autonomous mobile vehicle platforms ranging from warehouse robots to heavy duty trucks. Example applications within the field of automotive and robotics will be presented on the following automated vehicle platforms: Part 1: – Autonomous Parallel Parking of a Car-Like Mobile Robot, – Yaw Stability Control of a Car with Active Steering, – A Man-portable Rover Operating on Rough Terrains, – Cooperative Automated Maneuvering Vehicles, – EcoTwin: Truck Platooning on Highways, – Clara: A Warehouse Robot with Robust Multi-Sensor Localization, – Wasteshark: An Aqua-Drone for Cleaning Plastic Waste from the Harbors and Rivers. Part 2: [UTOPIA] Automated Open Precision Farming Platform The [UTOPIA] consortium, aims to develop an open access infrastructure in which relevant precision agriculture data can be collected from the field to be stored in the cloud and accessed through multiple stake-holders in the agri-food industry. In [UTOPIA], agricultural tasks and crop monitoring strategies can be easily set by the user, and the drones/USV’s/AGV’s are then automatically deployed to perform the mission(s) cooperatively. This technology will enable farmers to adopt smart precision farming technologies for improving yield and quality.

May 4, 2021
Cansu Korkmaz, KUIS AI Fellow
Multiple-Model Learned Image Processing Benefiting from Class-Specific Image Priors
When an image processing model is trained for a given task on a training set, the performance of the model varies noticeably over the test set from image to image depending on how well the image patterns in the training set matches to those in the test set. Hence, image priors learned by a single generic model cannot generalize well enough for different classes of images. In this talk, I will briefly explain the effect of training multiple deep super-resolution (SR) models for different classes of images to exploit class-specific image priors. Then, I will present our proposed multiple-model SR (MMSR) approach which is a post-processing network that learns how to best fuse the outputs of these class-specific multiple SR models. Afterwards, I will interpret our experimental results which demonstrate that the proposed approach with a set of pre-trained models and a generic fusion model significantly outperforms a single pre-trained EDSR model both quantitatively and visually. It even exceeds the performance of the best single class-specific EDSR model trained on heterogenous images.
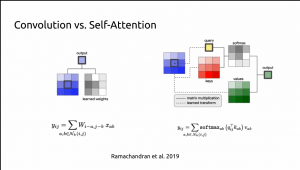
April 27, 2021
Emre Ünal, KUIS AI Fellow
Fully Attention Based Methods for Video Understanding
In this presentation, I will talk about my ongoing work on video understanding. I will present a recent model that I have been working on for the action recognition problem. The model is fully attention-based and does not use any conventional neural architectures such as RNNs or CNNs. It uses multi-layer attention blocks for the task. I will talk about the implementation details and early experiment results on the popular human activity recognition dataset Charades.

April 20, 2021
Gül Varol, Ecole des Ponts ParisTech
Scaling up Sign Language Recognition
In this talk, I will first briefly introduce challenges in sign language research from a computer vision perspective. A key stumbling block in making progress towards unconstrained sign language recognition is the lack of appropriate training data, stemming from the high complexity of sign annotation and a limited supply of qualified annotators. I will then present recent work on scalable approaches to automatic data collection for sign recognition in continuous videos. We make use of weakly-aligned subtitles for broadcast footage together with (1) visual keyword spotting through mouthing cues [ECCV’20], (2) looking up words in visual dictionaries [ACCV’20], and (3) leveraging attention mechanism to localise signs [CVPR’21]. With these, we automatically localise about 1 million sign instances from a vocabulary of over 1000 signs in 1000 hours of video. The resulting data can be used to train strong sign recognition models for co-articulated signs. I will conclude with discussing open problems and other tasks besides recognition in sign language research.
April 13, 2021
Gedas Bertasius, Facebook AI
Visual Perception Models for Semantic Video Understanding
Many modern computer vision applications require the ability to understand video content. In this talk, I will present a series of methods that we design for this purpose. First, I will introduce MaskProp, a unifying approach for classifying, segmenting and tracking object instances in the video. It achieves the best-reported accuracy on the YouTube-VIS dataset, outperforming the closest competitor despite being trained on 1000x fewer images and 10x fewer bounding boxes. Afterwards, I will present COBE, a new large-scale framework for learning contextualized object representations in settings involving human-object interactions. Our approach exploits automatically-transcribed speech narrations from instructional YouTube videos, and it does not require manual annotations. Lastly, I will introduce TimeSformer, the first convolution-free architecture for video modeling built exclusively with self-attention. It achieves the best reported numbers on major action recognition benchmarks, and it is also more efficient than the state-of-the-art 3D CNNs.

The Trade-offs of Transfer Learning: Lessons from Meta-Learning and Multi-Task Learning
Transfer learning promises to improve the sample complexity of machine learning by searching for shared inductive biases across tasks, domains, and environments. Although empirical risk minimization is the workhorse of both single task supervised learning and transfer learning, transfer learning objectives are subject to qualitatively different trade-offs. The design space of transfer learning is typically multi-objective and hierarchical, necessitating a significantly different approach to understanding the sample complexity of the underlying problem. We start with meta-learning and rigorously define the trade-off between accurate modeling and optimization ease. At one end, classic meta-learning algorithms account for the structure of meta-learning but solve a complex optimization problem. In contrast, at the other end domain randomized search ignores the structure of meta-learning and solves a single-level optimization problem. Taking MAML as the representative meta-learning algorithm, we theoretically characterize the trade-off for general non-convex risk functions. We provide explicit bounds on the errors associated with modeling and optimization. We later move to the general problem of learning from multiple objectives and present a principled multi-objective optimization algorithm that applies to large-scale deep learning problems. We further analyze this algorithm in the context of learning from multiple domains and show exciting results, both positive and negative. Our further analysis reveals an interesting connection between multi-objective optimization and domain generalization.

Physical Reasoning: How to Go from Seeing to Acting
Autonomous robots are envisioned to be ubiquitous in our daily lives. Such robots are expected to make sequential decisions, plan their motions, and control their movements to realize their expected goals. This remarkable skill set requires a new research direction where perception, discrete decision-making, motion planning, control, and learning methods are considered jointly to provide autonomy to the agent while physically interacting with the world. In this talk, I will present our initial steps toward tackling this goal. In particular, I will cover three lines of research: (i) explainable and effective representations directly from visual perception data, (ii) task decompositions and robust motion planning algorithms for long-horizon tasks, and (iii) (safe) learning for control of autonomous robots in the real-world.
On the Path to Universality for Machine Translation: Multilinguality, Scale, Objectives, and Optimization
Massively multilingual translation

March 9, 2021
Ece Takmaz, Institute for Logic, Language and Computation (ILLC), University of Amsterdam (UvA)
Click here for slides.
Generating Image Descriptions Guided by Speaker-Specific Sequential Human Gaze
When speakers describe an image, there are certain visual and linguistic processes at work. For instance, speakers tend to look at an object before mentioning them. Inspired by these processes, we have developed the first models of image description generation informed by the cross-modal alignment between language and the human gaze. We build our models on a state-of-the-art image captioning model, which itself was inspired by the visual processes in humans. Our results show that aligning gaze with language production would help generate more diverse and more natural descriptions that are better aligned with human descriptions sequentially and semantically. In addition, such findings could shed light on human cognitive processes by comparing different ways of encoding the gaze modality and aligning it with language production.
At the end of my talk, I may briefly touch upon another project where we worked on resolving and generating incremental referring utterances in visual and conversational contexts, exemplifying another line of research that is conducted in my group.
At the end of my talk, I may briefly touch upon another project where we worked on resolving and generating incremental referring utterances in visual and conversational contexts, exemplifying another line of research that is conducted in my group.
March 2, 2021
Prof. Gülşen Eryiğit and Berke Oral, ITU Natural Language Processing Research Group
Click here for slides.
Information Extraction from Text Intensive and Visually Rich Banking Documents
Abstract Document types, where visual and textual information plays an important role in their analysis and understanding, pose a new and attractive area for information extraction research. Although cheques, invoices, and receipts have been studied in some previous multi-modal studies, banking documents present an unexplored area due to the naturalness of the text they possess in addition to their visual richness. This article presents the first study which uses visual and textual information for deep-learning-based information extraction on text-intensive and visually rich scanned documents which are, in this instance, unstructured banking documents, or more precisely, money transfer orders. The impact of using different neural word representations (i.e., FastText, ELMo, and BERT) on IE subtasks (namely, named entity recognition and relation extraction stages), positional features of words on document images, and auxiliary learning with some other tasks are investigated. The article proposes a new relation extraction algorithm based on graph factorization to solve the complex relation extraction problem where the relations within documents are n-ary, nested, document-level, and previously indeterminate in quantity. Our experiments revealed that the use of deep learning algorithms yielded around 10 percentage points of improvement on the IE sub-tasks. The inclusion of word positional features yielded around 3 percentage points of improvement in some specific information fields. Similarly, our auxiliary learning experiments yielded around 2 percentage points of improvement on some information fields associated with the specific transaction type detected by our auxiliary task. The integration of the information extraction system into a real banking environment reduced cycle times substantially. When compared to the manual workflow, the document processing pipeline shortened book-to-book money transfers to 10 minutes (from 29 min.) and electronic fund transfers (EFT) to 17 minutes (from 41 min.) respectively.
Building Differentiable Models of the 3D World
Modern machine learning has created exciting new opportunities for the design of intelligent robots. In particular, gradient-based learning methods have tremendously While modern learning-based scene understanding systems have shown experimentally promising results in simulated scenarios, they fail in unpredictable and unintuitive ways when deployed in real-world applications. Classical systems, on the other hand, offer guarantees and bounds on performance and generalization, but often require heavy handcrafting and oversight. My research aims to deeply integrate classical and learning-based techniques to bring the best of both worlds, by building “differentiable models of the 3D world”. I will talk about two particular recent efforts along these directions. improved 3D scene understanding in terms of perception, reasoning, and action. However, these advancements have undermined many “classical” techniques developed over the last few decades. I postulate that a flexible blend of “classical” and learned methods is the most promising path to developing flexible, interpretable, and actionable models of the world: a necessity for intelligent embodied agents. 1. gradSLAM – a fully differentiable dense SLAM system that can be plugged as a “layer” into neural nets 2. gradSim – a differentiable simulator comprising a physics engine and a renderer, to enable physical parameter estimation and visuomotor control from the video.
Perceptual Video Super-Resolution
Perceptual video processing is a challenging task, mostly due to the lack of effective measures of temporal consistency and naturalness of motion in processed videos. In this talk, we first explain the successful video restoration and super-resolution network EDVR (Enhanced Deformable Convolutional Networks), and the role of deformable convolution in its architecture. Then, we present our recent work which is an extension of EDVR for perceptual video super-resolution in two ways: i) including a texture discriminator network and adversarial texture loss in order to improve the naturalness of texture, and ii) including l2 flow loss, a flow discriminator network and adversarial flow loss to ensure motion naturalness. We observe that adding only adversarial texture loss yields more natural texture in each frame, but not necessarily a smooth natural motion. Perceptual motion improves significantly when using both l2 motion loss and adversarial texture and flow losses in addition to l2 texture loss. Finally, we discuss the perceptual performance metrics and evaluation of the results.
Self-Organizing Operational Neural Networks and Image Super-Resolution
It has become a standard practice to use convolutional networks in image restoration and super-resolution. Although the universal approximation theorem states that a multi-layer neural network can approximate any non-linear function with the desired precision, it does not reveal the best network architecture to do so. Recently, operational neural networks that choose the best non-linearity from a set of alternatives, and their “self-organized” variants that approximate any non-linearity via Taylor series have been proposed to address the well-known limitations and drawbacks of conventional ConvNets such as network homogeneity using only the McCulloch-Pitts neuron model. In this talk, I first briefly mention the operational neural networks (ONNs) and self-organized operational neural networks (Self-ONNs). Then I introduce the concept of self-organized operational residual (SOR) blocks, and present hybrid network architectures combining regular residual and SOR blocks to strike a balance between the benefits of stronger non-linearity and the overall number of parameters. The experimental results on the super-resolution task demonstrate that the proposed architectures yield performance improvements in both PSNR and perceptual metrics.
Towards More Reusable and Adaptive Models for Visual Recognition
In this talk, I will go over our recent efforts to make neural networks more reusable and adaptive. First, I will present “Towards Reusable Network Components by Learning Compatible Representations”, published at AAAI 2021. This work studies how components of different networks can be made compatible so that they can be re-assembled into new networks easily. This unlocks improvements in several different applications. Secondly, I will discuss “Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections”, published at ECCV 2020. There, we show the benefits of learning from interactions of a user with an interactive segmentation model: Such a model becomes self-adaptive, which enables it to successfully transfer to new distributions and domains. Due to this, our model achieves state-of-the-art results on several datasets. Finally, I will briefly discuss other important efforts in our team, such as the OpenImages dataset and Localized Narratives.