Spring 2022

Computational Imaging: Integrating Physical and Learned Models using Plug-and-Play Methods
Computational imaging is a rapidly growing area that seeks to enhance the capabilities of imaging instruments by viewing imaging as an inverse problem. Plug-and-Play Priors (PnP) is one of the most popular frameworks for solving computational imaging problems through the integration of physical and learned models. PnP leverages high-fidelity physical sensor models and powerful machine learning methods to provide state-of-the-art imaging algorithms. PnP algorithms alternate between minimizing a data-fidelity term to promote data consistency and imposing a learned regularizer in the form of an “artifact-reducing” deep neural network. Recent highly successful applications of PnP algorithms include bio-microscopy, computerized tomography, magnetic resonance imaging, and joint ptycho-tomography. This talk presents a unified and principled review of PnP by tracing its roots, describing its major variations, summarizing main results, and discussing applications in computational imaging.
May 24, 2022
Nils Reimers, Huggingface &TU Darmstadt
Advances in Neural Search
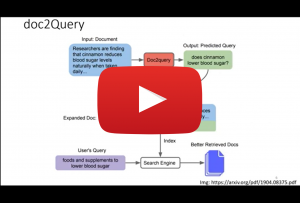
The advance of large pre-trained transformer models fundamentally changed Information Retrieval, resulting in substantially better search results without the need of large user-interaction data. In this talk, I will give an overview of different neural search techniques, their advantages and disadvantages, open challenges, and how they can successfully be used to improve any search system.
May 12, 2022
Ahmad P. Tafti, University of Southern Maine
Explainable AI in Medical Image Analysis: Lessons Learned in Total Joint Arthroplasty (TJA) Research
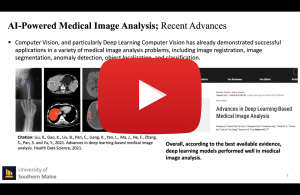
Orthopedic surgical procedures, and particularly total knee/hip arthroplasty (TKA/THA), are the most common and fastest growing surgeries in the United States. Almost 1.3 million TJA procedures occur on a yearly basis and more than 7 million Americans are currently living with artificial knee and/or hip joints. The widespread adoption of x-ray radiography and their availability at low cost, make them the principal method in assessing TJA and subtle TJA complications, such as osteolysis, implant loosening or infection over time, enabling surgeons to rule out complications and possible needs for revision surgeries. Rapid yet, with the growing number of TJA patients, the routine clinical and radiograph follow-up remain a daunting task for most orthopedic centers. It becomes an overwhelming amount of work, on a human scale, when we consider a radiologist or surgeon presented with the vast number of medical images daily. Smart computational strategies, such as explainable artificial intelligence and deep learning methods are thus required to analyze arthroplasty radiographs automatically and objectively, enabling both naive and experienced practitioners to perform radiographic follow-up with greater ease and speed, providing them with better explainability and interpretability in AI models. In this talk, we will be discussing the effectiveness of explainable AI methods to advance TJA research. We, together, will explore what explainable AI components do in TJA research and how.

May 10, 2022
Deniz Altınbüken, Google Brain Research
The Tip of the Iceberg: How to make ML for Systems work
Machine Learning has become a powerful tool to improve computer systems and there is a significant amount of research ongoing both in academia and industry to tackle systems problems using Machine Learning. Most work focuses on learning patterns and replacing heuristics with these learned patterns to solve systems problems such as compiler optimization, query optimization, failure detection, indexing, caching. However, solutions that truly improve systems need to maintain the efficiency, availability, reliability, and maintainability of systems while integrating Machine Learning into the system. In this talk, I will cover the key aspects and surprising joys of designing, implementing and deploying ML for Systems solutions based on my experiences of building and deploying these systems at Google.
Apr 26, 2022
Erhan Öztop, Özyeğin University& Osaka University
Mirror Neurons from a Developmental Robotics Perspective
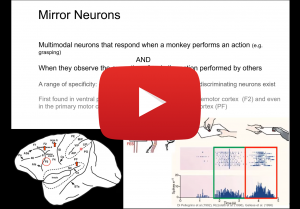
Mirror Neurons have been initially discovered in the ventral premotor cortex of macaque monkeys, which seem to represent action and perception in a common framework: they become active when a monkey executes a grasp action, as well as when the monkey observes another monkey or human perform a similar action. The computational modeling of the ‘mirror system’ makes a nice example of how developmental robotics interprets learning, which differs from the current supervised learning systems that can be trained with large, labeled data sets. In developmental robotics, learning data is mostly generated by the learning agent itself and is limited. When external information exists, severe restrictions exist as to what type of data is accessible to the agent. In this talk, I will present a pre-deep learning era mirror neuron modeling, followed by a new model that incorporates the state-of-the art deep neural networks. The latter work indicates that with developmentally valid constraints interesting behaviors may emerge even without feature engineering supporting the hypothesis that mirror neurons develop based on self-observation learning.
Apr 19, 2022
Nuri Benbarka, University of Tübingen
Instance Segmentation and 3D Multi-Object Tracking for Autonomous Driving
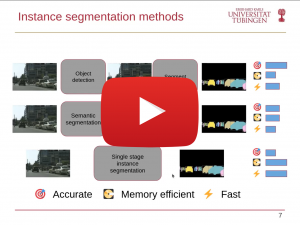
Autonomous driving promises to change the way we live. It could save lives, provide mobility, reduce wasted time driving, and enable new ways to design our cities. One crucial component in an autonomous driving system is perception, understanding the environment around the car to take proper driving commands. This talk will discuss two perception tasks: instance segmentation and 3D multi-object tracking. In instance segmentation, we discuss different mask representations and propose representing the mask’s boundary as Fourier series. We show that this implicit representation is compact, fast, and gives the highest mAP for a small number of parameters on the dataset MS COCO. Furthermore, during our work on instance segmentation, we found that the Fourier series is linked with the emerging field of implicit neural representations (INR). We show that the general form of the Fourier series is a Fourier mapped perceptron with integer frequencies. As a result, we know that one perceptron is enough to represent any signal if the Fourier mapping matrix has enough frequencies. In 3D MOT, we focus on tracklet management systems, classifying them into count-based and confidence-based systems. We found that the score update functions used previously for confidence-based systems are not optimal. Therefore, we propose better score update functions that give better score estimates. In addition, we used the same technique for the late fusion of object detectors. Finally, we tested our algorithm on the NuScenes and Waymo datasets, giving a consistent AMOTA boost.re given.

Mar 29, 2022
Prof. Dr. Björn Schuller, Imperial College London & University of Augsburg
Real Artificial Audio Intelligence: Computers Can Also Hear
We already got used to computers somewhat understanding our speech, and we can experience how well computers can already see, for example in autonomous vehicles. But can they also hear as good as we can or beyond? This talk introduces a new perspective on Computer Audition, by dissecting sounds into the individual sound sources and attributing them rich states and traits. Likewise, the sound of a cup put onto a desk becomes the sound sources “cup” and “desk” with attribution such as “the cup is made of china, has a crack, and seems half-full of liquid” or “the desk is made of pinewood and about 3 cm thick”, etc. As modelling such rich descriptions comes at tremendous data cravings, advances in self-supervised learning for audio as well as zero- and few-shot learning concepts are introduced among other data efficiency techniques. The talk shows a couple of first advances. Beyond, applications reaching from saving our health to saving our planet are given.

Mar 22, 2022
Ali Safaya, Koç University & Taner Sezer from Mersin University
Turkish Data Depository Project: Towards a Unified Turkish NLP Research Platform
The Turkish language has been left out of the state-of-the-art Natural Language Processing due to a lack of organized research communities. The lack of organized platforms makes it hard for foreign and junior researchers to contribute to Turkish NLP. We present the Turkish Data Depository (tdd.ai) project as a remedy for this. The main goal of TDD subprojects is collecting and organizing Turkish Natural Language Processing (NLP) datasets and providing a research basis for Turkish NLP. In this talk, I will present the results of our ongoing efforts to build TDD. I will go over our recently published user-friendly hub for Turkish NLP datasets (data.tdd.ai). Moreover, I will present our recently accepted ACL’22 paper on Mukayese (mukayese.tdd.ai), a benchmarking platform for various Turkish NLP tools and tasks, ranging from Spell-checking to Natural Language Understanding tasks (NLU).

Mar 8, 2022
Prof. Dr. Murat Tekalp, Koç University
State of The Art in Deep Learning for Image/Video Super-Resolution
Recent advances in neural architectures and training methods led to significant improvements in the performance of learned image/video restoration and SR. We can consider learned image restoration and SR as learning either a mapping from the space of degraded images to ideal images based on the universal approximation theorem or a generative model that captures the probability distribution of ideal images. An important benefit of data-driven deep learning approach is that neural models can be optimized for any differentiable loss function, including visual perceptual loss functions, leading to perceptual video restoration and SR, which cannot be easily handled by traditional model-based approaches. I will discuss loss functions and evaluation criteria for image/video restoration and SR, including fidelity and perceptual criteria, and the relation between them, where we briefly review the perception vs. fidelity (distortion) trade-off. We then discuss practical problems in applying supervised training to real-life restoration and SR, including overfitting image priors and overfitting the degradation model and some possible ways to deal with these problems.
Feb 22, 2022
Damla Övek & Zeynep Abalı, Koç University
Prediction of Protein-Protein Interactions Using Deep Learning
Proteins interact through their interfaces to fulfill essential functions in the cell. They bind to their partners in a highly specific manner and form complexes that have a profound effect on understanding the biological pathways they are involved in. Any abnormal interactions may cause diseases. As experimental data accumulates, artificial intelligence (AI) begins to be used and recent groundbreaking applications of AI profoundly impact the structural biology field. In this talk, we will discuss the deep learning methods applied for the prediction of protein-protein interactions and their interfaces.

Feb 15, 2022
Alper Erdoğan, Koç University
Polytopic Matrix Factorization and Information Maximization Based Unsupervised Learning
We introduce Polytopic Matrix Factorization (PMF) as a flexible unsupervised data decomposition approach. In this new framework, we model input data as unknown linear transformations of some latent vectors drawn from a polytope. The choice of polytope reflects the presumed features of the latent components and their mutual relationships. As the factorization criterion, we propose the determinant maximization (Det-Max) for the sample autocorrelation matrix of the latent vectors. We introduce a sufficient condition for identifiability, which requires that the convex hull of the latent vectors contains the maximum volume inscribed ellipsoid of the polytope with a particular tightness constraint. Based on the Det-Max criterion and the proposed identifiability condition, we show that all polytopes that satisfy a particular symmetry restriction qualify for the PMF framework. Having infinitely many polytope choices provides a form of flexibility in characterizing latent vectors. In particular, it is possible to define latent vectors with heterogeneous features, enabling the assignment of attributes such as nonnegativity and sparsity at the subvector level. We also propose an information-theoretic perspective for the determinant maximization-based matrix factorization frameworks. As further extensions, we will discuss the normative construction of neural networks based on local update rules.

Feb 10, 2022
Leyla Keser, İstanbul Bilgi University
Key Elements of the future legally binding instrument of the Council of Europe (CoE) Ad-Hoc Committee on AI (CAHAI)
The key elements of the CoE AI Convention, which will be the first Convention on AI in the world, have been prepared by an ad-hoc committee called CAHAI, which was established in 2019. CAHAI completed its mission with its last meeting on November 30-December 2, 2021, leaving behind a text detailing with the key elements that the binding international AI convention will come into force. In this event, this text prepared by CAHAI will be discussed with the participants explaining key elements regarding the entire lifecycle of AI.

Jan 8, 2022
Hooman Hedayati, University of North Carolina Chapel Hill
Improving Human-Robot Conversational Groups
This work aims to improve human-robot conversational groups, in which a robot is situated in an F-formation with humans. With a naive look, each robot consists of input devices e.g., sensors, cameras, etc. logic and decision-making blocks e.g., face detection algorithm, NLP, etc., and output devices e.g., actuators and speakers, etc. These components connect serially. Each component is prone to errors; therefore, each error feeds into the next component and decreases the overall efficiency of the system. For example, if the camera cannot see a person because of being obstructed by an object, then the human detection algorithm cannot detect that person and then the robot won’t consider that person in the interaction. These types of errors decrease the efficiency of the system and also negatively impact human-robot interaction. In this work, we propose four systems that aim to help understand human-robot conversational groups better, reason about them, find the mentioned errors and overcome them. First, we look at the difference between human-human conversational groups and human-robot conversation groups. Second, we propose an algorithm to detect conversational groups (F-formations). Third, we look at how to detect missing people in the conversational groups and validate human-detection algorithms. Last, we propose an algorithm to detect the active speaker based on visual cues and help robots behave normally in conversational groups.