Spring 2021

May 18, 2021
Cengiz Öztireli from Google Research, University of Cambridge
3D Digital Reality Modeling for Perception
Creating digital models of reality is one of the grand challenges of computer science. In this talk, I will summarize some of our efforts towards achieving this goal to allow machines to perceive the world as well as and beyond humans. The focus will be on capturing and replicating the visual world and techniques at the intersection of computer graphics, vision, and machine learning to solve several fundamental problems and their practical applications.
May 11, 2021
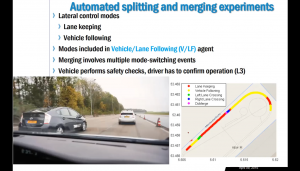
Sinan Öncü, Smart and Autonomous Mobility Research Laboratory, Boğaziçi University.
Cooperative Perception and Control for Autonomous Vehicles
This talk will be on past and currently ongoing research projects of Sinan Öncü on various autonomous mobile vehicle platforms ranging from warehouse robots to heavy duty trucks. Example applications within the field of automotive and robotics will be presented on the following automated vehicle platforms: Part 1: – Autonomous Parallel Parking of a Car-Like Mobile Robot, – Yaw Stability Control of a Car with Active Steering, – A Man-portable Rover Operating on Rough Terrains, – Cooperative Automated Maneuvering Vehicles, – EcoTwin: Truck Platooning on Highways, – Clara: A Warehouse Robot with Robust Multi-Sensor Localization, – Wasteshark: An Aqua-Drone for Cleaning Plastic Waste from the Harbors and Rivers. Part 2: [UTOPIA] Automated Open Precision Farming Platform The [UTOPIA] consortium, aims to develop an open access infrastructure in which relevant precision agriculture data can be collected from the field to be stored in the cloud and accessed through multiple stake-holders in the agri-food industry. In [UTOPIA], agricultural tasks and crop monitoring strategies can be easily set by the user, and the drones/USV’s/AGV’s are then automatically deployed to perform the mission(s) cooperatively. This technology will enable farmers to adopt smart precision farming technologies for improving yield and quality.

May 4, 2021
Cansu Korkmaz, KUIS AI Fellow
Multiple-Model Learned Image Processing Benefiting from Class-Specific Image Priors
When an image processing model is trained for a given task on a training set, the performance of the model varies noticeably over the test set from image to image depending on how well the image patterns in the training set matches to those in the test set. Hence, image priors learned by a single generic model cannot generalize well enough for different classes of images. In this talk, I will briefly explain the effect of training multiple deep super-resolution (SR) models for different classes of images to exploit class-specific image priors. Then, I will present our proposed multiple-model SR (MMSR) approach which is a post-processing network that learns how to best fuse the outputs of these class-specific multiple SR models. Afterwards, I will interpret our experimental results which demonstrate that the proposed approach with a set of pre-trained models and a generic fusion model significantly outperforms a single pre-trained EDSR model both quantitatively and visually. It even exceeds the performance of the best single class-specific EDSR model trained on heterogenous images.
April 27, 2021
Emre Ünal, KUIS AI Fellow
Fully Attention Based Methods for Video Understanding
In this presentation, I will talk about my ongoing work on video understanding. I will present a recent model that I have been working on for the action recognition problem. The model is fully attention-based and does not use any conventional neural architectures such as RNNs or CNNs. It uses multi-layer attention blocks for the task. I will talk about the implementation details and early experiment results on the popular human activity recognition dataset Charades.

April 20, 2021
Gül Varol, Ecole des Ponts ParisTech
Scaling up Sign Language Recognition
In this talk, I will first briefly introduce challenges in sign language research from a computer vision perspective. A key stumbling block in making progress towards unconstrained sign language recognition is the lack of appropriate training data, stemming from the high complexity of sign annotation and a limited supply of qualified annotators. I will then present recent work on scalable approaches to automatic data collection for sign recognition in continuous videos. We make use of weakly-aligned subtitles for broadcast footage together with (1) visual keyword spotting through mouthing cues [ECCV’20], (2) looking up words in visual dictionaries [ACCV’20], and (3) leveraging attention mechanism to localise signs [CVPR’21]. With these, we automatically localise about 1 million sign instances from a vocabulary of over 1000 signs in 1000 hours of video. The resulting data can be used to train strong sign recognition models for co-articulated signs. I will conclude with discussing open problems and other tasks besides recognition in sign language research.
April 13, 2021
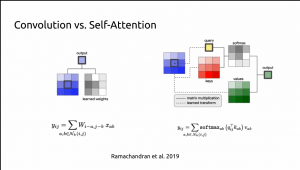
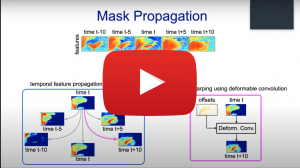
Gedas Bertasius, Facebook AI
Visual Perception Models for Semantic Video Understanding
Many modern computer vision applications require the ability to understand video content. In this talk, I will present a series of methods that we design for this purpose. First, I will introduce MaskProp, a unifying approach for classifying, segmenting and tracking object instances in the video. It achieves the best-reported accuracy on the YouTube-VIS dataset, outperforming the closest competitor despite being trained on 1000x fewer images and 10x fewer bounding boxes. Afterwards, I will present COBE, a new large-scale framework for learning contextualized object representations in settings involving human-object interactions. Our approach exploits automatically-transcribed speech narrations from instructional YouTube videos, and it does not require manual annotations. Lastly, I will introduce TimeSformer, the first convolution-free architecture for video modeling built exclusively with self-attention. It achieves the best reported numbers on major action recognition benchmarks, and it is also more efficient than the state-of-the-art 3D CNNs.

The Trade-offs of Transfer Learning: Lessons from Meta-Learning and Multi-Task Learning
Transfer learning promises to improve the sample complexity of machine learning by searching for shared inductive biases across tasks, domains, and environments. Although empirical risk minimization is the workhorse of both single task supervised learning and transfer learning, transfer learning objectives are subject to qualitatively different trade-offs. The design space of transfer learning is typically multi-objective and hierarchical, necessitating a significantly different approach to understanding the sample complexity of the underlying problem. We start with meta-learning and rigorously define the trade-off between accurate modeling and optimization ease. At one end, classic meta-learning algorithms account for the structure of meta-learning but solve a complex optimization problem. In contrast, at the other end domain randomized search ignores the structure of meta-learning and solves a single-level optimization problem. Taking MAML as the representative meta-learning algorithm, we theoretically characterize the trade-off for general non-convex risk functions. We provide explicit bounds on the errors associated with modeling and optimization. We later move to the general problem of learning from multiple objectives and present a principled multi-objective optimization algorithm that applies to large-scale deep learning problems. We further analyze this algorithm in the context of learning from multiple domains and show exciting results, both positive and negative. Our further analysis reveals an interesting connection between multi-objective optimization and domain generalization.

Physical Reasoning: How to Go from Seeing to Acting
Autonomous robots are envisioned to be ubiquitous in our daily lives. Such robots are expected to make sequential decisions, plan their motions, and control their movements to realize their expected goals. This remarkable skill set requires a new research direction where perception, discrete decision-making, motion planning, control, and learning methods are considered jointly to provide autonomy to the agent while physically interacting with the world. In this talk, I will present our initial steps toward tackling this goal. In particular, I will cover three lines of research: (i) explainable and effective representations directly from visual perception data, (ii) task decompositions and robust motion planning algorithms for long-horizon tasks, and (iii) (safe) learning for control of autonomous robots in the real-world.
On the Path to Universality for Machine Translation: Multilinguality, Scale, Objectives, and Optimization
Massively multilingual translation

March 9, 2021
Ece Takmaz, Institute for Logic, Language and Computation (ILLC), University of Amsterdam (UvA)
Click here for slides.
Generating Image Descriptions Guided by Speaker-Specific Sequential Human Gaze
When speakers describe an image, there are certain visual and linguistic processes at work. For instance, speakers tend to look at an object before mentioning them. Inspired by these processes, we have developed the first models of image description generation informed by the cross-modal alignment between language and the human gaze. We build our models on a state-of-the-art image captioning model, which itself was inspired by the visual processes in humans. Our results show that aligning gaze with language production would help generate more diverse and more natural descriptions that are better aligned with human descriptions sequentially and semantically. In addition, such findings could shed light on human cognitive processes by comparing different ways of encoding the gaze modality and aligning it with language production.
At the end of my talk, I may briefly touch upon another project where we worked on resolving and generating incremental referring utterances in visual and conversational contexts, exemplifying another line of research that is conducted in my group.
At the end of my talk, I may briefly touch upon another project where we worked on resolving and generating incremental referring utterances in visual and conversational contexts, exemplifying another line of research that is conducted in my group.
March 2, 2021
Prof. Gülşen Eryiğit and Berke Oral, ITU Natural Language Processing Research Group
Click here for slides.
Information Extraction from Text Intensive and Visually Rich Banking Documents
Abstract Document types, where visual and textual information plays an important role in their analysis and understanding, pose a new and attractive area for information extraction research. Although cheques, invoices, and receipts have been studied in some previous multi-modal studies, banking documents present an unexplored area due to the naturalness of the text they possess in addition to their visual richness. This article presents the first study which uses visual and textual information for deep-learning-based information extraction on text-intensive and visually rich scanned documents which are, in this instance, unstructured banking documents, or more precisely, money transfer orders. The impact of using different neural word representations (i.e., FastText, ELMo, and BERT) on IE subtasks (namely, named entity recognition and relation extraction stages), positional features of words on document images, and auxiliary learning with some other tasks are investigated. The article proposes a new relation extraction algorithm based on graph factorization to solve the complex relation extraction problem where the relations within documents are n-ary, nested, document-level, and previously indeterminate in quantity. Our experiments revealed that the use of deep learning algorithms yielded around 10 percentage points of improvement on the IE sub-tasks. The inclusion of word positional features yielded around 3 percentage points of improvement in some specific information fields. Similarly, our auxiliary learning experiments yielded around 2 percentage points of improvement on some information fields associated with the specific transaction type detected by our auxiliary task. The integration of the information extraction system into a real banking environment reduced cycle times substantially. When compared to the manual workflow, the document processing pipeline shortened book-to-book money transfers to 10 minutes (from 29 min.) and electronic fund transfers (EFT) to 17 minutes (from 41 min.) respectively.
Building Differentiable Models of the 3D World
Modern machine learning has created exciting new opportunities for the design of intelligent robots. In particular, gradient-based learning methods have tremendously While modern learning-based scene understanding systems have shown experimentally promising results in simulated scenarios, they fail in unpredictable and unintuitive ways when deployed in real-world applications. Classical systems, on the other hand, offer guarantees and bounds on performance and generalization, but often require heavy handcrafting and oversight. My research aims to deeply integrate classical and learning-based techniques to bring the best of both worlds, by building “differentiable models of the 3D world”. I will talk about two particular recent efforts along these directions. improved 3D scene understanding in terms of perception, reasoning, and action. However, these advancements have undermined many “classical” techniques developed over the last few decades. I postulate that a flexible blend of “classical” and learned methods is the most promising path to developing flexible, interpretable, and actionable models of the world: a necessity for intelligent embodied agents. 1. gradSLAM – a fully differentiable dense SLAM system that can be plugged as a “layer” into neural nets 2. gradSim – a differentiable simulator comprising a physics engine and a renderer, to enable physical parameter estimation and visuomotor control from the video.
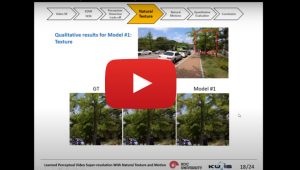
Perceptual Video Super-Resolution
Perceptual video processing is a challenging task, mostly due to the lack of effective measures of temporal consistency and naturalness of motion in processed videos. In this talk, we first explain the successful video restoration and super-resolution network EDVR (Enhanced Deformable Convolutional Networks), and the role of deformable convolution in its architecture. Then, we present our recent work which is an extension of EDVR for perceptual video super-resolution in two ways: i) including a texture discriminator network and adversarial texture loss in order to improve the naturalness of texture, and ii) including l2 flow loss, a flow discriminator network and adversarial flow loss to ensure motion naturalness. We observe that adding only adversarial texture loss yields more natural texture in each frame, but not necessarily a smooth natural motion. Perceptual motion improves significantly when using both l2 motion loss and adversarial texture and flow losses in addition to l2 texture loss. Finally, we discuss the perceptual performance metrics and evaluation of the results.
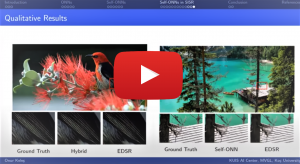
Self-Organizing Operational Neural Networks and Image Super-Resolution
It has become a standard practice to use convolutional networks in image restoration and super-resolution. Although the universal approximation theorem states that a multi-layer neural network can approximate any non-linear function with the desired precision, it does not reveal the best network architecture to do so. Recently, operational neural networks that choose the best non-linearity from a set of alternatives, and their “self-organized” variants that approximate any non-linearity via Taylor series have been proposed to address the well-known limitations and drawbacks of conventional ConvNets such as network homogeneity using only the McCulloch-Pitts neuron model. In this talk, I first briefly mention the operational neural networks (ONNs) and self-organized operational neural networks (Self-ONNs). Then I introduce the concept of self-organized operational residual (SOR) blocks, and present hybrid network architectures combining regular residual and SOR blocks to strike a balance between the benefits of stronger non-linearity and the overall number of parameters. The experimental results on the super-resolution task demonstrate that the proposed architectures yield performance improvements in both PSNR and perceptual metrics.
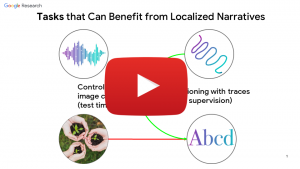
Towards More Reusable and Adaptive Models for Visual Recognition
In this talk, I will go over our recent efforts to make neural networks more reusable and adaptive. First, I will present “Towards Reusable Network Components by Learning Compatible Representations”, published at AAAI 2021. This work studies how components of different networks can be made compatible so that they can be re-assembled into new networks easily. This unlocks improvements in several different applications. Secondly, I will discuss “Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections”, published at ECCV 2020. There, we show the benefits of learning from interactions of a user with an interactive segmentation model: Such a model becomes self-adaptive, which enables it to successfully transfer to new distributions and domains. Due to this, our model achieves state-of-the-art results on several datasets. Finally, I will briefly discuss other important efforts in our team, such as the OpenImages dataset and Localized Narratives.